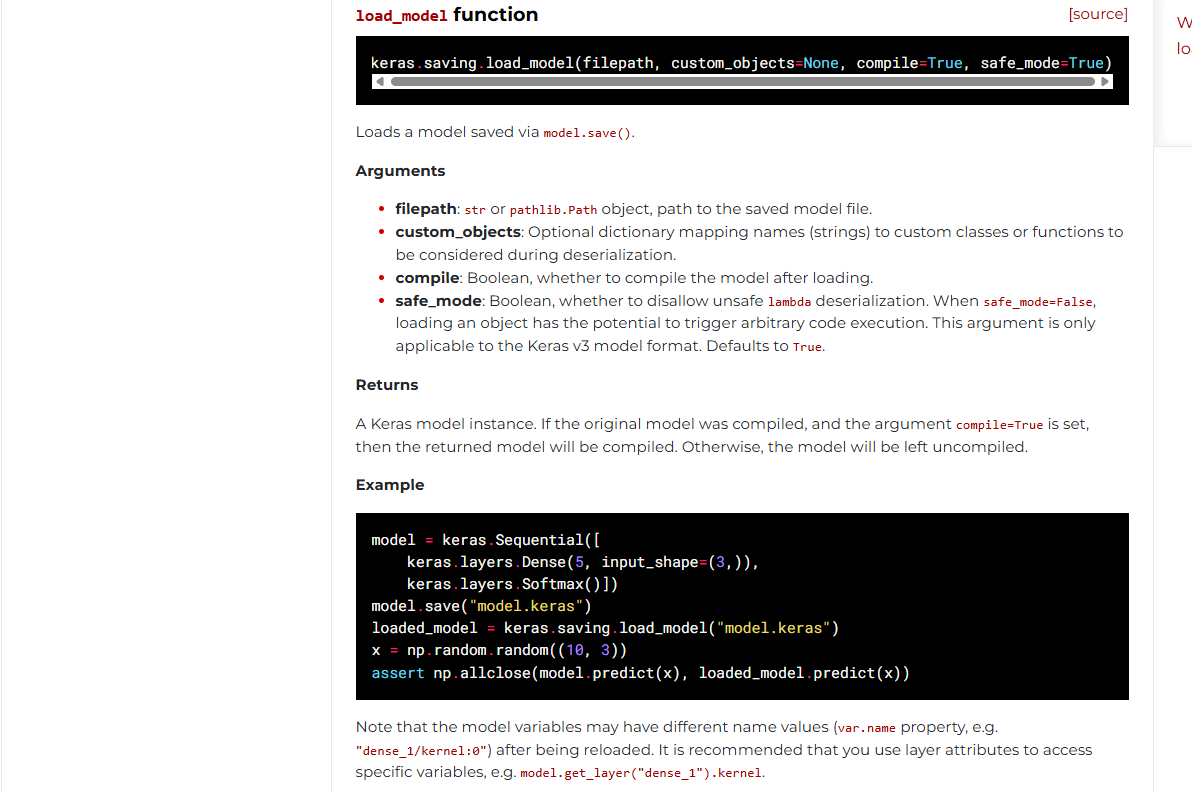
model = ... # Get model (Sequential, Functional Model, or Model subclass) model.save('path/to/location.keras') # The file needs to end with the .keras extension
ifisinstance(cls, types.FunctionType): return cls ifnothasattr(cls, "from_config"): raise TypeError( f"Unable to reconstruct an instance of '{class_name}' because " f"the class is missing a `from_config()` method. " f"Full object config: {config}" )
# Instantiate the class from its config inside a custom object scope # so that we can catch any custom objects that the config refers to. custom_obj_scope = object_registration.CustomObjectScope(custom_objects) safe_mode_scope = SafeModeScope(safe_mode) with custom_obj_scope, safe_mode_scope: try: instance = cls.from_config(inner_config) except TypeError as e: raise TypeError( f"{cls} could not be deserialized properly. Please" " ensure that components that are Python object" " instances (layers, models, etc.) returned by" " `get_config()` are explicitly deserialized in the" " model's `from_config()` method." f"\n\nconfig={config}.\n\nException encountered: {e}" ) build_config = config.get("build_config", None) if build_config andnot instance.built: instance.build_from_config(build_config) instance.built = True compile_config = config.get("compile_config", None) if compile_config: instance.compile_from_config(compile_config) instance.compiled = True
deffunctional_from_config(cls, config, custom_objects=None): """Instantiates a Functional model from its config (from `get_config()`). Args: cls: Class of the model, e.g. a custom subclass of `Model`. config: Output of `get_config()` for the original model instance. custom_objects: Optional dict of custom objects. Returns: An instance of `cls`. """ # Layer instances created during # the graph reconstruction process created_layers = {}
# Dictionary mapping layer instances to # node data that specifies a layer call. # It acts as a queue that maintains any unprocessed # layer call until it becomes possible to process it # (i.e. until the input tensors to the call all exist). unprocessed_nodes = {}
defadd_unprocessed_node(layer, node_data): """Add node to layer list Arg: layer: layer object node_data: Node data specifying layer call """ if layer notin unprocessed_nodes: unprocessed_nodes[layer] = [node_data] else: unprocessed_nodes[layer].append(node_data)
defprocess_node(layer, node_data): """Reconstruct node by linking to inbound layers Args: layer: Layer to process node_data: List of layer configs """ args, kwargs = deserialize_node(node_data, created_layers) # Call layer on its inputs, thus creating the node # and building the layer if needed. layer(*args, **kwargs)
defprocess_layer(layer_data): """Deserializes a layer and index its inbound nodes. Args: layer_data: layer config dict. """ layer_name = layer_data["name"]
# Instantiate layer. if"module"notin layer_data: # Legacy format deserialization (no "module" key) # used for H5 and SavedModel formats layer = saving_utils.model_from_config( layer_data, custom_objects=custom_objects ) else: layer = serialization_lib.deserialize_keras_object( layer_data, custom_objects=custom_objects ) created_layers[layer_name] = layer
# Gather layer inputs. inbound_nodes_data = layer_data["inbound_nodes"] for node_data in inbound_nodes_data: # We don't process nodes (i.e. make layer calls) # on the fly because the inbound node may not yet exist, # in case of layer shared at different topological depths # (e.g. a model such as A(B(A(B(x))))) add_unprocessed_node(layer, node_data)
# Extract config used to instantiate Functional model from the config. The # remaining config will be passed as keyword arguments to the Model # constructor. functional_config = {} for key in ["layers", "input_layers", "output_layers"]: functional_config[key] = config.pop(key) for key in ["name", "trainable"]: if key in config: functional_config[key] = config.pop(key) else: functional_config[key] = None
# First, we create all layers and enqueue nodes to be processed for layer_data in functional_config["layers"]: process_layer(layer_data)
# Then we process nodes in order of layer depth. # Nodes that cannot yet be processed (if the inbound node # does not yet exist) are re-enqueued, and the process # is repeated until all nodes are processed. while unprocessed_nodes: for layer_data in functional_config["layers"]: layer = created_layers[layer_data["name"]]
# Process all nodes in layer, if not yet processed if layer in unprocessed_nodes: node_data_list = unprocessed_nodes[layer]
# Process nodes in order node_index = 0 while node_index < len(node_data_list): node_data = node_data_list[node_index] try: process_node(layer, node_data)
# If the node does not have all inbound layers # available, stop processing and continue later except IndexError: break
node_index += 1
# If not all nodes processed then store unprocessed nodes if node_index < len(node_data_list): unprocessed_nodes[layer] = node_data_list[node_index:] # If all nodes processed remove the layer else: del unprocessed_nodes[layer]
# Create list of input and output tensors and return new class name = functional_config["name"] trainable = functional_config["trainable"]
with zipfile.ZipFile(model_name, 'r') as zip_read: with zipfile.ZipFile(f"tmp.{model_name}", 'w') as zip_write: for item in zip_read.infolist(): if item.filename != "config.json": zip_write.writestr(item, zip_read.read(item.filename))