学习Java反序列化绕WAF新姿势
问题由来
这两天在做PolarCTF2025夏季赛碰到了一个对序列化字符串明文的检查,具体实现代码是这样的
1 | package com.polar.ctf.utils; |
什么意思呢?
本地写个测试文件
1 | package TestCode; |
然后用序列化操作进行处理,其序列化后的数据长这样

可以看到其中的类名是呈现明文的形式
换成之前的链子序列化出来的东西也是一样的
例如CC1

所以基于这种情况就诞生了一种WAF方式,就是通过对序列化字符串明文的检查达到一个过滤的效果,简单来说就是直接从序列化字符串中进行黑名单检测
既然会对序列化字符串明文进行检查,那如何既能绕过该检查还能被正常的反序列化出来呢?
初步探索
先看一下ObjectInputStream的有参构造函数都干了什么
1 | public ObjectInputStream(InputStream in) throws IOException { |
可以看到这里进行了一些初始配置,包括enableOverride初始是为false
我们回头看一下反序列化的操作
ObjectInputStream#readObject
先看到readObject方法
1 | public final Object readObject() |
先是检测是否开启了覆盖模式,主要是用于子类自定义反序列化行为,ObjectInputStream 有一个受保护的构造方法,可以让子类重写 readObjectOverride() 去实现自己的协议。
随后保存外层对象的句柄,用于处理嵌套对象的情况
调用readObject0函数进行反序列化操作,false表示unshared,我们跟进readObject0函数看看
内容比较长,我们分段进行解析
1 | boolean oldMode = bin.getBlockDataMode(); |
这是处理block data块数据模式的逻辑
ObjectInputStream 在反序列化过程中会进入两种模式:
- Object Mode(对象模式)
按序列化协议读对象。 - Block Data Mode(块数据模式)
- 主要在
writeObject()里写入 primitive 类型(如 int, double)时被启用。 - 数据被写成“块”,每个块带长度。
- 对应
readObject()需要从这种块里读取原始数据。
- 主要在
1 | byte tc; |
tc = bin.peekByte()读取下一字节并检测是否是TC_RESET重置对象引用的句柄,注意:这里不会移动指针,先读取后操作
如果是相等的话会readByte读取字节并处理 reset 逻辑,这里的话用的是while循环,所以每个TC_RESET句柄都会处理
那什么是TC_RESET呢?其实就是清空反序列化时的已读对象句柄表,这意味着下一次读取同一个对象的时候会把该对象看作是新对象去处理并分配句柄
1 | depth++; |
记录递归深度,用于跟踪嵌套对象的层级
1 | try { |
这里的话就是根据类型去调用不同的方法处理数据类型,例如TC_NULL表示null对象类型,就需要调用readNull函数去进行处理
ObjectInputStream#readClass
我们看到TC_CLASS标识下对对象的处理readClass函数
1 | private Class<?> readClass(boolean unshared) throws IOException { |
跟进readClassDesc函数
1 | private ObjectStreamClass readClassDesc(boolean unshared) |
同样的操作,我们看到普通类的操作readNonProxyDesc
ObjectInputStream#readNonProxyDesc
1 | private ObjectStreamClass readNonProxyDesc(boolean unshared) |
先是创建类描述符并分配句柄,然后为这个类描述符分配一个句柄,由于是unshared非共享对象引用,所以会分配desc对象本身
重置了一下passHandle,然后进行类描述符的读取,跟进readClassDescriptor函数
1 | protected ObjectStreamClass readClassDescriptor() |
跟进readNonProxy方法
ObjectStreamClass#readNonProxy
1 | void readNonProxy(ObjectInputStream in) |
注意到关键的一步name = in.readUTF();,读取类的全限定类名,跟进看看
BlockDataInputStream#readUTFBody
1 | ObjectInputStream#readUTF() |
在BlockDataInputStream#readUTF()中先调用readUnsignedShort()从流里先读一个 unsigned short,也就是UTF字节长度,为2字节
然后readUTFBody函数中就是循环读取所有 UTF-8 字节并解码,跟进readUTFSpan函数
BlockDataInputStream#readUTFSpan
分段看一下
1 | int cpos = 0; |
记录开始的位置,可读取的字节数,还有就是计算停止的位置,这里做了一个预留操作,如果utflen > avail也就是需要处理的数据长度大于可读取的字节数,就预留两个字节出来,因为最后一个UTF字符可能是三字节的。最后outOfBounds 是用来捕获数组越界异常的
1 | while (pos < stop) { |
读取第一个字节并转换为无符号整数,& 0xFF的作用就是将有符号 byte 转换为无符号 int
b1 >> 4用来判断UTF-8编码类型,并分别给出了单字节,双字节以及三字节字符三种情况下的处理
绕过思路
基于上面的分析我们不难看出,Java的ObjectInputStream在反序列化获取类名的时候会经过以下几个函数
1 | ObjectInputStream#readObject() |
并且是会对UTF-8编码进行处理的,至此,我们可以实现序列化字符串中的所有className字符串的不可读,从而绕过字符串明文的检查
最终POC
通过继承ObjectOutputStream来修改序列化时写入的数据
1 | package SerializeChains.UTF_bypass; |
我们重新序列化一下刚刚的Evil实例对象
1 | package TestCode; |

可以看到此时数据基本不可读,成功Bypass
我们拿CC1的链子试一下

并不会影响反序列化,success!
强化一下
其实从CC1中还是可以看到有些字符是明文显示的,是否可以进一步强化呢?当然是可以的
p牛之前有篇文章也写到了这个问题:https://www.leavesongs.com/PENETRATION/utf-8-overlong-encoding.html


翻译一下
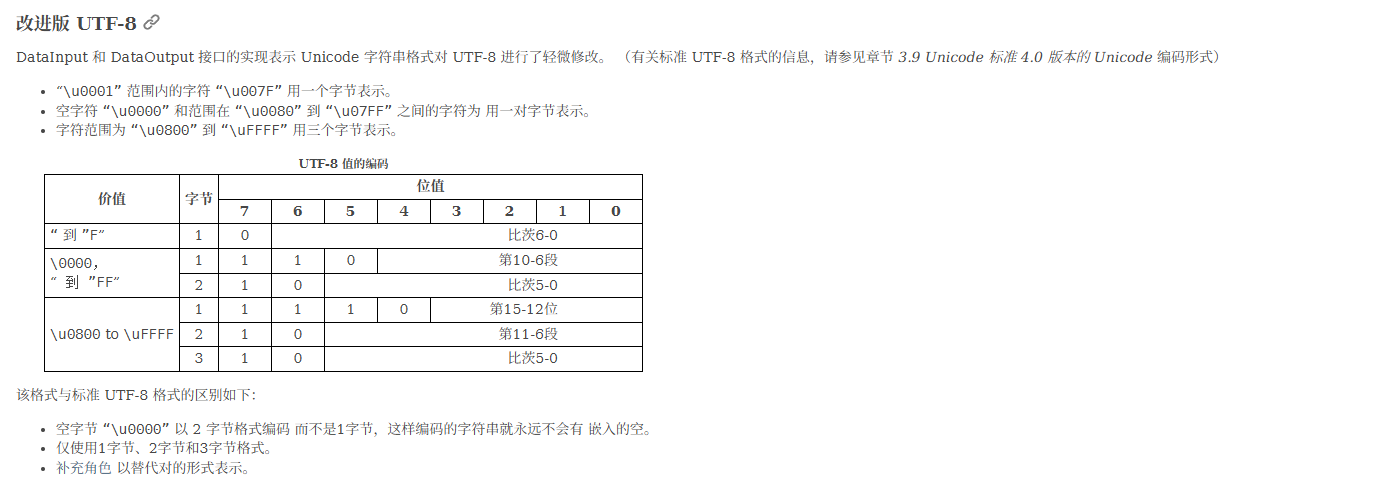
p牛的一个简单脚本
1 | def convert_int(i: int) -> bytes: |
参考文章:
https://vidar-team.feishu.cn/docx/LJN4dzu1QoEHt4x3SQncYagpnGd
https://docs.oracle.com/en/java/javase/23/docs/api/java.base/java/io/DataInput.html#modified-utf-8
https://www.leavesongs.com/PENETRATION/utf-8-overlong-encoding.html